Last updated: 27th Jan, 2024
Training an AI / Machine Learning model as sophisticated as the one used by ChatGPT involves a multi-step process that fine-tunes its ability to understand and generate human-like text. Let’s break down the ChatGPT training process into three primary steps. Note that OpenAI has not published any specific paper on this. However, the reference has been provided on this page – Introducing ChatGPT.
The first phase starts with collecting demonstration data. Here, prompts are taken from a dataset, and human labelers provide the desired output behavior, which essentially sets the standard for the AI’s responses. For example, if the prompt is to “Explain reinforcement learning to a 6-year-old,” the labeler would craft an explanation that’s comprehensible at that level.
This demonstration data is then used to fine-tune a base model like GPT-3.5 through supervised learning. In this stage, the model learns to predict the next word in a sequence, given the previous words, and aims to mimic the demonstrated behavior.
The next step involves collecting comparison data. The ChatGPT model generates several sample outputs in response to a prompt, and human labelers then rank these from best to worst. This ranking helps the ChatGPT model understand the nuances of what makes a response more valuable or appropriate than another.
This ranked data is crucial in training a reward model. This model learns to predict the quality of the ChatGPT outputs based on the human labeler’s rankings. Essentially, it’s a guide that helps the ChatGPT understand the preferences and values reflected in human judgments.
A reward model is typically a classifier that predicts one of two classes—positive or negative. These are often called binary classifiers and are often based on smaller language models like BERT. Many language-aware binary classifiers already exist to classify sentiment or detect toxic language. Training a custom reward model is a relatively labor-intensive and costly endeavor. One should explore existing binary classifiers before committing to this effort. You may want to check out details in the book, Generative AI on AWS. Here are some of the steps to train a custom reward model:
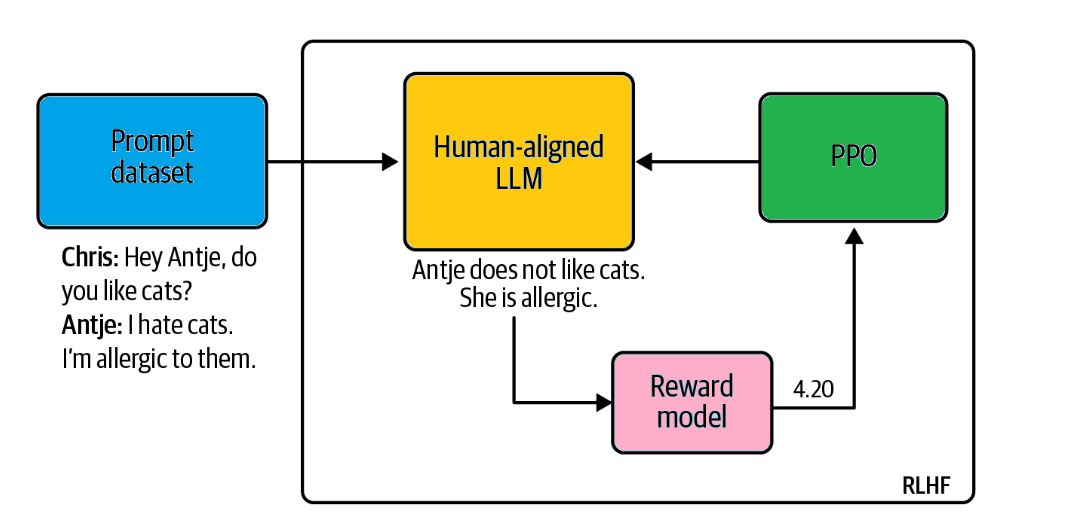
Finally, we come to the reinforcement learning phase, where the reward model is used to further train the ChatGPT model using the Proximal Policy Optimization (PPO) algorithm. Here’s how it works:
The following is the depiction of how PPO RL algorithm works with LLM in RLHF. As the name suggests, PPO optimizes a policy, in this case, the LLM, to generate completions that are more aligned with human values and preferences. With each iteration, PPO makes small and bounded updates to the LLM weights—hence the term Proximal Policy Optimization.
This cycle continues with the ChatGPT model progressively refining its responses to be more aligned with human preferences.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}