When building a Retrieval-Augmented Generation (RAG) application powered by Large Language Models (LLMs), which combine the ability to generate human-like text with advanced retrieval mechanisms for precise and contextually relevant information, effective indexing plays a pivotal role. It ensures that only the most contextually relevant data is retrieved and fed into the LLM, improving the quality and accuracy of the generated responses. This process reduces noise, optimizes token usage, and directly impacts the application’s ability to handle large datasets efficiently. RAG applications combine the generative capabilities of LLMs with information retrieval, making them ideal for tasks such as question-answering, summarization, or domain-specific problem-solving. This blog will walk you through the indexing workflow step by step.
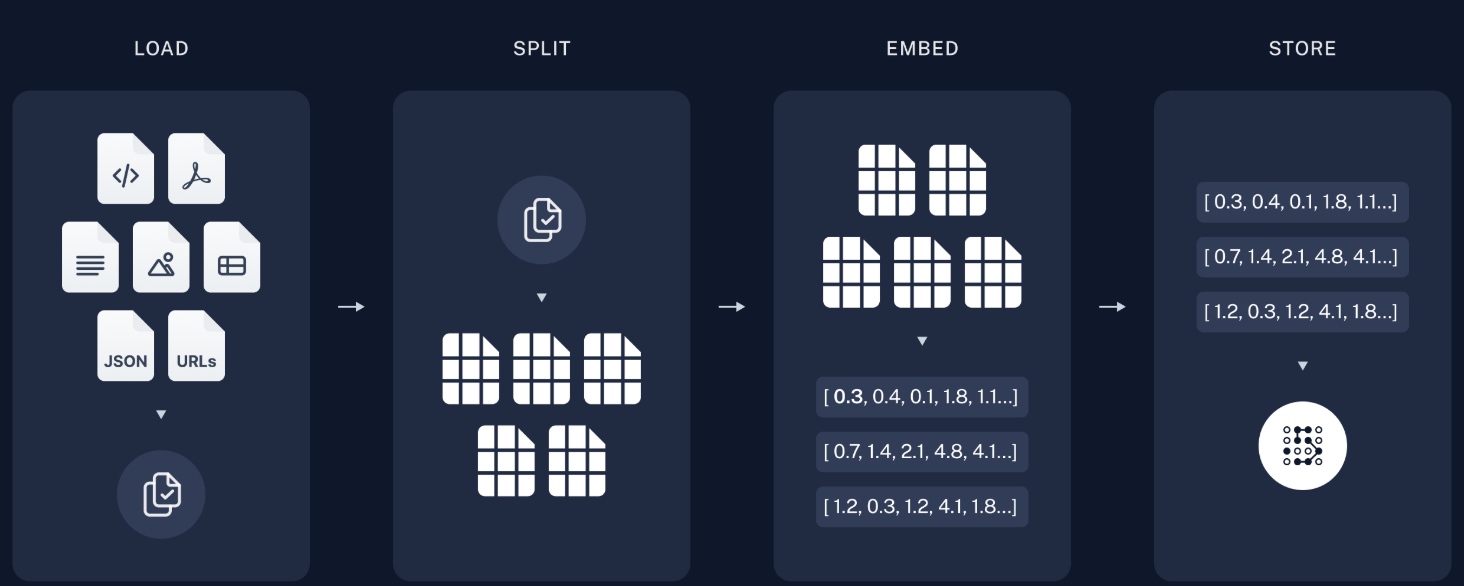
Indexing in RAG applications typically follows four key stages: Load, Split, Embed, and Store. Each stage contributes uniquely to ensuring efficient and accurate retrieval of information. Let’s break these stages down:
The first step is to gather the data that your application will access during retrieval. This data can include:
The goal here is to load the raw data into the pipeline. Regardless of the data format, everything is pre-processed into a standardized format that can be indexed. For example, PDFs might be converted to plain text, while images might require text extraction.
Once the data is loaded, it must be divided into manageable chunks. This is because LLMs, including GPT-based models, have token limits. By splitting data into smaller pieces:
How is the data split?
To enable efficient retrieval, each chunk is transformed into a numerical representation, or an embedding, using a vectorizer model (e.g., OpenAI’s embedding models or Hugging Face embeddings).
For example:
[0.3, 0.4, 0.1, 1.8, 1.1...].[0.7, 1.4, 2.1, 4.8, 4.1...].These embeddings ensure that semantically related information is grouped together for efficient search.
Finally, the embeddings are stored in a vector database such as Pinecone, Weaviate, or Vespa. A vector database is designed to store and manage high-dimensional vectors efficiently, making it particularly suitable for handling embeddings. It allows for fast similarity searches by comparing these vectors, enabling the retrieval of semantically relevant information quickly and accurately. This database:
During retrieval, the application queries the vector database with a user’s question or input. The database returns the closest matches based on the embeddings’ similarity, which the LLM then uses to generate a relevant response.
Indexing is the backbone of RAG applications, bridging the gap between static datasets and the dynamic responses of LLMs. By following the Load → Split → Embed → Store pipeline, you ensure that your application retrieves the right data at the right time, enhancing its overall performance.
Understanding and implementing indexing will improve your RAG application, whether you’re building a Q&A bot or a domain-specific assistant.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}