Clustering is a type of unsupervised machine learning technique that is used to group data points into distinct categories or clusters. It is one of the most widely used techniques in machine learning and can be used for various tasks such as grouping customers by their buying habits, creating groups of similar documents, or finding groups of related genes. In this blog post, we will explore different types / categories of clustering methods and discuss why they are so important in the field of machine learning.
Prototype based clustering represents one of the categories of clustering algorithms that are used to identify groups within a larger dataset. This technique takes its inspiration from prototype theory, which states that the best way to describe a class is by identifying one “prototype” example. Prototype based clustering algorithms create a set of centroids or medoids within the data set to represent each prototype. The centroid represents the average of similar points with continuous features. The medoid represents the point that minimizes the distance to all other points that belong to a particular cluster in the case of categorical features. Using this metric, the algorithm can determine which data points are closest to each other and from that generate clusters.
Prototype based clustering most commonly uses K-means clustering. K-means clustering is one particular type of prototype based clustering. This algorithm seeks to minimize variance within each cluster by repeatedly making small adjustments to the centroid positions until they reach an optimal configuration. One of the drawbacks of K-means clustering algorithm is that we have to specify the number of clusters, K, a priori. K-means algorithm can be summarized as following:
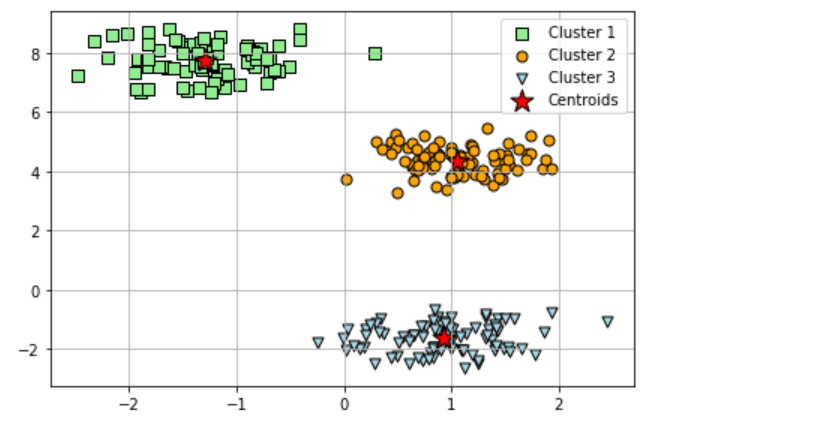
The techniques such as the elbow method and silhouette plots, can be used to evaluate the quality of clustering and determine the optimal number of clusters, K. Here is a sample code for creating K-means clusters and potting them along with centroids. Also, find the plot created as part of executing the code.
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
#
# Create 350 randomly generated points (n_samples=350)
# Grouped into 3 regions (centers=3)
X, y = make_blobs(n_samples=250,
n_features=3,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0)
#
# Train with K-means clustering
#
km = KMeans(n_clusters=3,
init='random',
n_init=10,
max_iter=300,
tol=1e-04,
random_state=0)
y_km = km.fit_predict(X)
#
# Plot K-means clusters with Centroids
#
plt.scatter(X[y_km == 0, 0],
X[y_km == 0, 1],
s=50, c='lightgreen',
marker='s', edgecolor='black',
label='Cluster 1')
plt.scatter(X[y_km == 1, 0],
X[y_km == 1, 1],
s=50, c='orange',
marker='o', edgecolor='black',
label='Cluster 2')
plt.scatter(X[y_km == 2, 0],
X[y_km == 2, 1],
s=50, c='lightblue',
marker='v', edgecolor='black',
label='Cluster 3')
plt.scatter(km.cluster_centers_[:, 0],
km.cluster_centers_[:, 1],
s=250, marker='*',
c='red', edgecolor='black',
label='Centroids')
plt.legend(scatterpoints=1)
plt.grid()
plt.tight_layout()
plt.show()
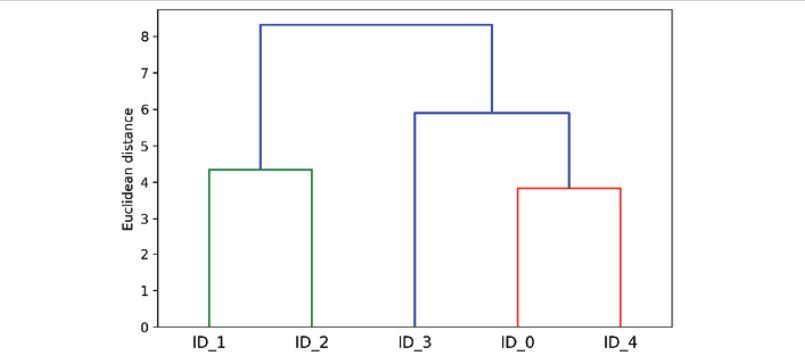
Hierarchical clustering is another type of unsupervised learning technique that works by creating a hierarchy of clusters in form of hierarchical tree. The advantages of this type of clustering over prototype based clustering are the following:
There are two different kind of hierarchical clustering. They are as following:
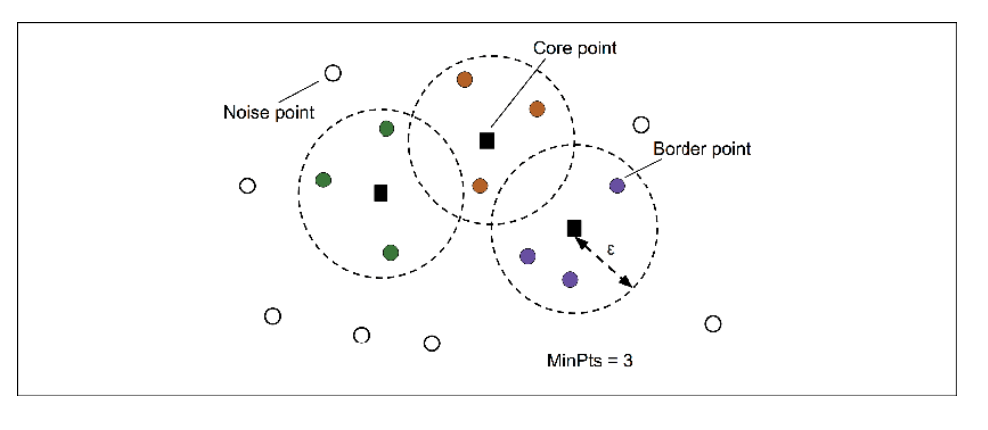
Density-based clustering is an algorithm that uses density to identify clusters in datasets where points are close together but have no clear boundaries separating them from other data points. Density based clustering gets its name from DBSCAN. DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is an example of this type of algorithm and it works by assigning each point a minimum number of neighbors before considering it part of a cluster. As the name implies, density-based clustering assigns cluster labels based on dense regions of points. In DBSCAN, the notion of density is defined as the number of points within a specified radius,
The following is how DBSCAN or density-based clustering works:
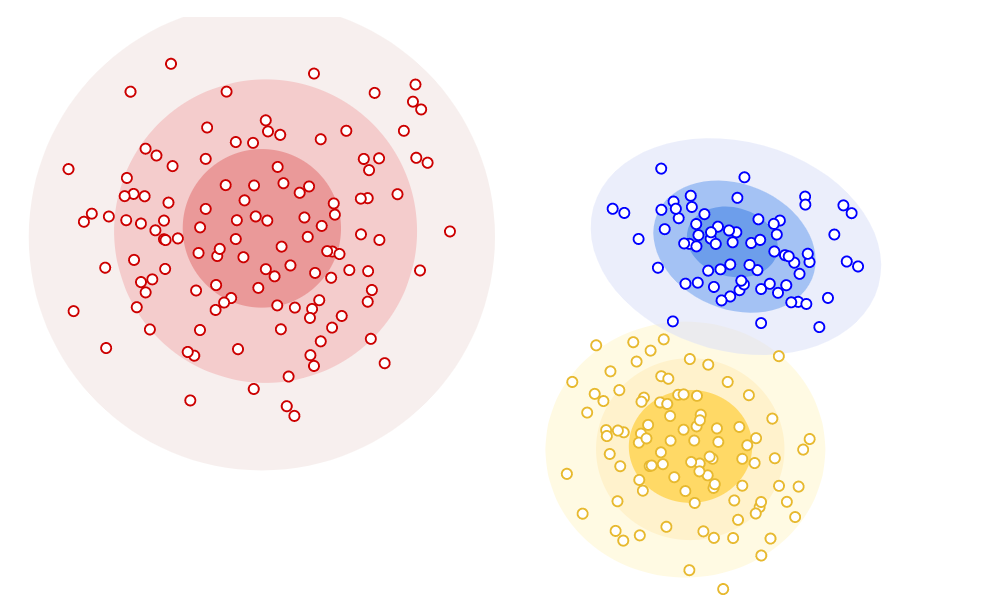
Distribution based clustering is a type of hierarchical clustering that is used when the distribution of data points is known such as Gaussian or normal distribution. It is based on the concept of dividing data into clusters, where each cluster has a mean and variance. The following picture three different distribution based clusters.
The benefits of using distribution based clustering include the ability to handle large datasets, the ability to identify non-linear relationships, and the ability to identify outliers.
Clustering algorithms are essential tools for any machine learning engineer or data scientist looking to uncover trends and patterns within their dataset without relying on manual labeling or supervised classification methods. By understanding different types of clustering algorithms such as prototype-based, hierarchical, distribution based and DBSCAN, you will be able to apply these techniques to your own projects with confidence and accuracy. With enough practice, you’ll soon be uncovering insights in your data no one else has ever seen before!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}
{kind=link}