Have you ever wondered why your machine learning model is not performing as expected? Could the “average” behavior of your dataset be misleading your model? How does the “central” or “typical” value of a feature influence the performance of a machine learning model?
In this blog, we will explore the concept of central tendency, its significance in machine learning, and the importance of addressing skewness in your dataset. All of this will be demonstrated with the help of Python code examples using a diabetes dataset.
We will be working with the diabetes dataset which can be found on Kaggle – Diabetes Dataset. The dataset consists for multiple columns such as ‘Glucose’, ‘BloodPressure’, ‘SkinThickness’, ‘Insulin’, ‘BMI’ having 0 as the values. These can be seen as missing value. It would be good to remove these missing values before proceeding ahead with the analysis. The following is the Python code to load the data and remove the missing values.
import pandas as pd
# Load the dataset
df_diabetes = pd.read_csv('/content/diabetes.csv')
# Remove rows where any of the specified columns have a value of 0
columns_to_check = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
df_diabetes_filtered = df_diabetes[df_diabetes[columns_to_check].apply(lambda row: all(row != 0), axis=1)]
# Show the shape of the original and filtered datasets to indicate how many rows were removed
original_shape = df_diabetes.shape
filtered_shape = df_diabetes_filtered.shape
original_shape, filtered_shape
The original dataset contained 768 rows and 9 columns. After removing rows with zero values in one or more of the specified columns (‘Glucose’, ‘BloodPressure’, ‘SkinThickness’, ‘Insulin’, ‘BMI’), the filtered dataset now contains 392 rows and 9 columns. We will work with df_diabetes_filtered data frame in this blog.
Central tendency refers to the measure that identifies the “central” or “typical” value for each feature in a dataset. Three commonly used measures of central tendency are:
# Calculate the mean of the 'Insulin' feature
mean_insulin = df_diabetes_filtered['Insulin'].mean()# Calculate the median of the 'Insulin' feature median_insulin = df_diabetes_filtered['Insulin'].median()# Calculate the mode of the 'Insulin' feature mode_insulin = df_diabetes_filtered['Insulin'].mode()[0]The following Python code can help you get the central tendency for all features in the dataset. The code works for Google Collab if you uploaded the diabetes dataset in the root folder of your jupyter notebook in Google Collab .
# Calculate mean and median for each column
mean_median_stats = df_diabetes_filtered.agg(['mean', 'median']).transpose()
# Calculate mode for each column separately and get the first mode value in case there are multiple modes
mode_stats = df_diabetes_filtered.mode().iloc[0]
# Combine the statistics for display
central_tendency_stats = pd.concat([mean_median_stats, mode_stats.rename('mode')], axis=1)
central_tendency_stats
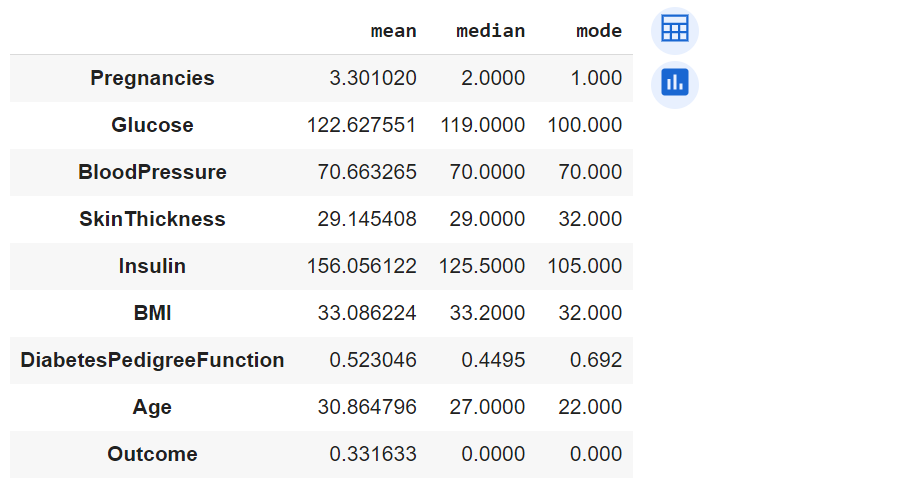
Here is how the central tendency of all the features would look like:
Here are some observations regarding the central tendency measures including mean and median.
Let’s review the skewness of ‘Insulin’ feature with visual representation using the following Python code.
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the matplotlib figure
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
fig.suptitle('Distribution and Outliers for Insulin (Filtered Data)')
# Plot histogram for Insulin
sns.histplot(df_diabetes_filtered['Insulin'], kde=True, ax=axes[0])
axes[0].set_title('Histogram of Insulin')
# Plot boxplot for Insulin
sns.boxplot(x=df_diabetes_filtered['Insulin'], ax=axes[1])
axes[1].set_title('Boxplot of Insulin')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
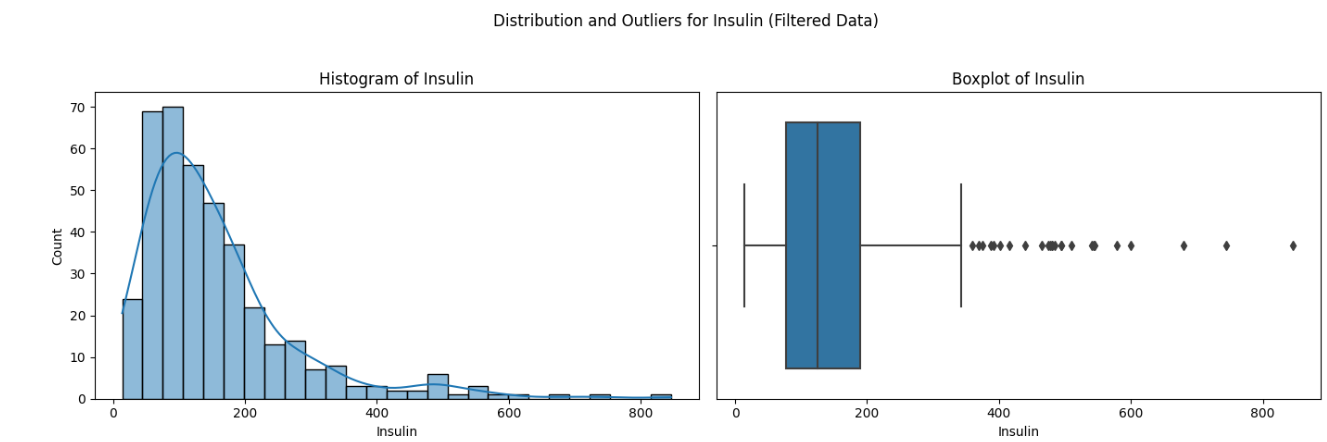
Here is how the plot would look like:
Here are the observations from the above plot:
The following can be impact on the predictive modeling:
Skewness is a measure of the asymmetry of the probability distribution of a feature. In simpler terms, if the distribution of data is skewed to the left or right, it can impact the machine learning model’s performance. Many machine learning algorithms assume that the data follows a Gaussian distribution. Skewed data can violate this assumption, affecting the model’s performance.
The following can be done as next steps to address the potential challenges posed by skewed data:
The following code demonstrate how we handle data skewness related to Insulin feature.
from scipy.stats import boxcox
import numpy as np
# Prepare data for transformations
insulin_data = df_diabetes_filtered['Insulin']
# Square root transformation
sqrt_transformed = np.sqrt(insulin_data)
# Log transformation
log_transformed = np.log1p(insulin_data) # Using log(1 + x) to handle zero values
# Box-Cox transformation
boxcox_transformed, _ = boxcox(insulin_data)
# Set up the matplotlib figure
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
fig.suptitle('Insulin Data Transformations to Address Skewness')
# Plot original data
sns.histplot(insulin_data, kde=True, ax=axes[0, 0])
axes[0, 0].set_title('Original Data')
# Plot square root transformed data
sns.histplot(sqrt_transformed, kde=True, ax=axes[0, 1])
axes[0, 1].set_title('Square Root Transformed Data')
# Plot log transformed data
sns.histplot(log_transformed, kde=True, ax=axes[1, 0])
axes[1, 0].set_title('Log Transformed Data')
# Plot Box-Cox transformed data
sns.histplot(boxcox_transformed, kde=True, ax=axes[1, 1])
axes[1, 1].set_title('Box-Cox Transformed Data')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
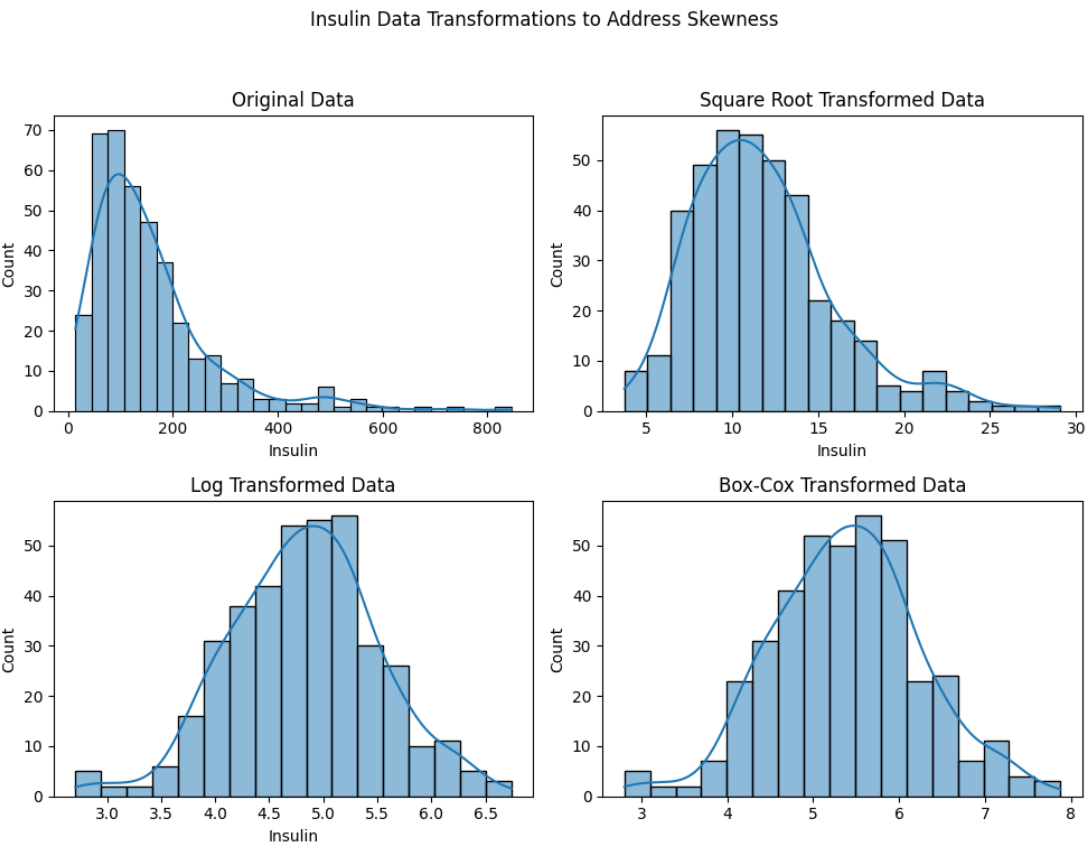
The following is how the plots would look like:
Here are the observations:
The following represents impact on building machine learning model with reduced skewness in the data:
Central tendency is not just a statistical concept; it plays a pivotal role in the realm of machine learning and data science. Understanding the mean, median, and mode of your dataset can offer invaluable insights into the ‘average’ behavior of features, thereby influencing the performance of your predictive models. Through our exploration with the diabetes dataset, we saw how these measures can indicate the need for further data preprocessing, such as handling skewness through transformations like Square Root, Log, or Box-Cox. However, as demonstrated, the impact of such transformations can vary depending on the machine learning algorithm being used.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}