Reddit app client id and secret token
In this post, you will get Python code sample using which you can search Reddit for specific subreddit posts including hot posts. Reddit API is used in the Python code. This code will be helpful if you quickly want to scrape Reddit for popular posts in the field of machine learning (subreddit – r/machinelearning), data science (subreddit – r/datascience), deep learning (subreddit – r/deeplearning) etc.
There will be two steps to be followed to scrape Reddit for popular posts in any specific subreddits.
Check the Reddit API documentation page to learn about Reddit APIs.
Here is the code you would need to use for authenticating and authorization purposes. Here are the key steps:
import requests
# note that CLIENT_ID refers to 'personal use script' and SECRET_TOKEN to 'token'
auth = requests.auth.HTTPBasicAuth('qfK5a5tkC-bkV3adVR5d2w', 'AX01I3U9WQ4eSkGfK67kk4AEgkIKbM')
# here we pass our login method (password), username, and password
data = {'grant_type': 'password',
'username': 'vitalflux',
'password': 'vitalflux'}
# setup our header info, which gives reddit a brief description of our app
headers = {'User-Agent': 'vitalflux-pybot/0.0.1'}
# send our request for an OAuth token
res = requests.post('https://www.reddit.com/api/v1/access_token',
auth=auth, data=data, headers=headers)
# convert response to JSON and pull access_token value
TOKEN = res.json()['access_token']
# add authorization to our headers dictionary
headers = {**headers, **{'Authorization': f"bearer {TOKEN}"}}
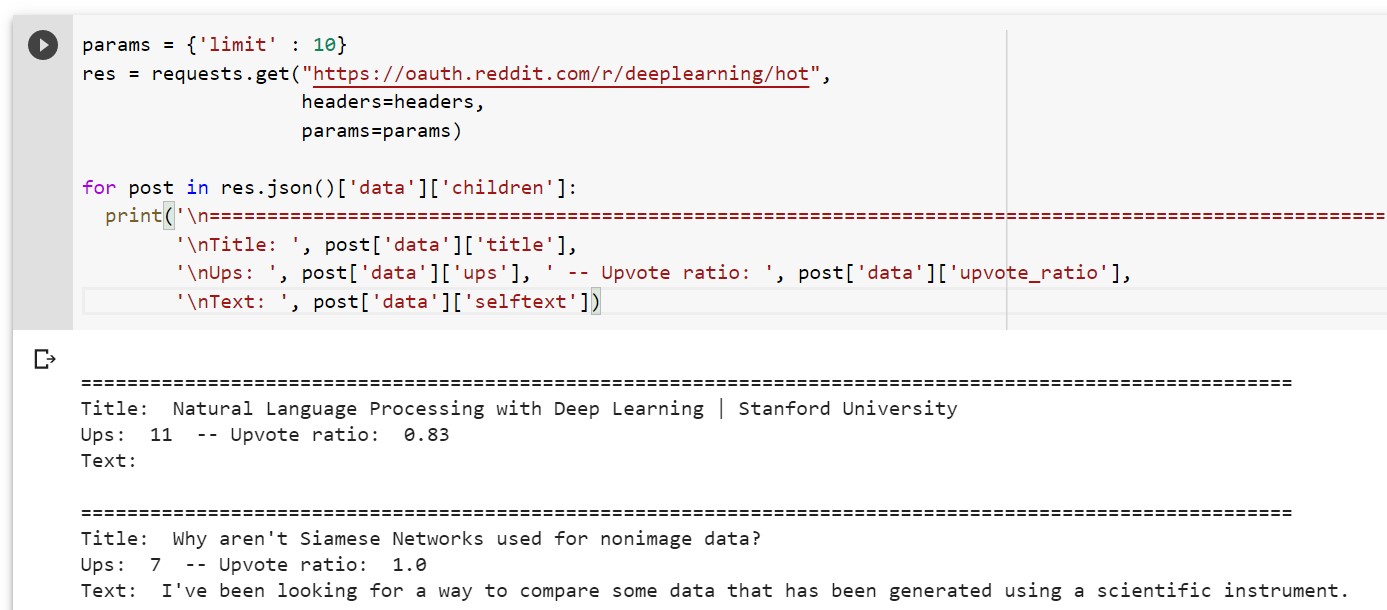
params = {'limit' : 10}
res = requests.get("https://oauth.reddit.com/r/deeplearning/hot",
headers=headers,
params=params)
for post in res.json()['data']['children']:
print('\n=========================================================================================================',
'\nTitle: ', post['data']['title'],
'\nUps: ', post['data']['ups'], ' -- Upvote ratio: ', post['data']['upvote_ratio'],
'\nText: ', post['data']['selftext'])
The following is what gets printed.
Here is the entire Python code which can be used to retrieve the subreddit’s popular posts. Ensure to put your own username/password and, client id/secret token
import requests
# note that CLIENT_ID refers to 'personal use script' and SECRET_TOKEN to 'token'
auth = requests.auth.HTTPBasicAuth('qfK5a5tkC-bkV3adVR5d2w', 'AX01I3U9WQ4eSkGfK67kk4AEgkIKbM')
# here we pass our login method (password), username, and password
data = {'grant_type': 'password',
'username': 'vitalflux',
'password': 'vitalflux'}
# setup our header info, which gives reddit a brief description of our app
headers = {'User-Agent': 'vitalflux-pybot/0.0.1'}
# send our request for an OAuth token
res = requests.post('https://www.reddit.com/api/v1/access_token',
auth=auth, data=data, headers=headers)
# convert response to JSON and pull access_token value
TOKEN = res.json()['access_token']
# add authorization to our headers dictionary
headers = {**headers, **{'Authorization': f"bearer {TOKEN}"}}
# Print the subreddit popular posts
params = {'limit' : 10}
res = requests.get("https://oauth.reddit.com/r/deeplearning/hot",
headers=headers,
params=params)
for post in res.json()['data']['children']:
print('\n=========================================================================================================',
'\nTitle: ', post['data']['title'],
'\nUps: ', post['data']['ups'], ' -- Upvote ratio: ', post['data']['upvote_ratio'],
'\nText: ', post['data']['selftext'])
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}