Not every data set fits neatly into a traditional SQL relational database. To address the need for more flexible databases, NoSQL data models were developed. These models allow for faster development cycles, larger data sets and greater scalability than traditional SQL databases. In this post, we’ll provide an overview of NoSQL data models and some examples of how they are used in real-world applications.
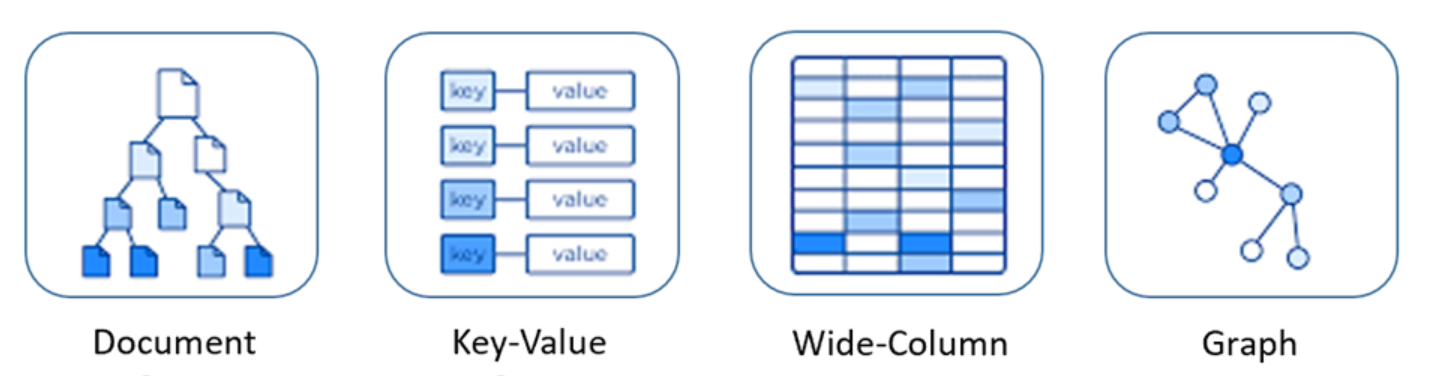
NoSQL data models can be divided into four main types: document stores, key-value stores, graph databases, and column stores. Each type has its own unique strengths and weaknesses and is best suited to certain types of applications or use cases. Here’s a brief overview of each type. The picture below represents these four different kinds of NoSQL data model.
The Document data model is one of the most popular NoSQL data models which is used to store data in NoSQL database such as MongoDB and Couchbase database. The document data model uses a unique key for each document and stores the data as a set of documents, typically encoded in JSON format, which allows for easy reference to individual elements in a given document. As compared to the Key-Value (KV) model which only stores key-value pairs, the Document data model can provide more structured and organized query results. Unlike key-value pair database, the value associated with the key is not opaque to the database. The picture below represents document data model used in NoSQL databases:
Unlike relational databases where all documents within a collection must have the same schema, this model allows for documents within a collection to have different structures. This makes it easier to store and retrieve unstructured or semi-structured data with each document having its own structure.
Document data model allows creating indexes on document fields so that they can quickly retrieve information without needing to search through all documents within a collection. This also helps with performance since indexing speeds up query execution time.
One example of a real-world application using NoSQL document data models is ecommerce sites. As customers add items to their carts, the database can store them as documents in JSON format with key-value pairs describing each item. This allows for faster retrieval of the customer’s order when they complete their purchase.
The Key-value data model is one of the most popular and widely used models for NoSQL databases such as Redis, Oracle NoSQL, etc. This data model is also known as KV store, associative array, hash map, or dictionary. It stores data in a key-value pair which makes it ideal for storing large amounts of unstructured data such as string, JSON, image, or whatever else is appropriate for the business requirements.
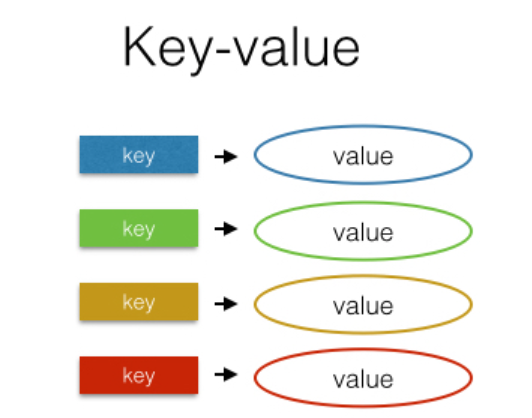
In a Key-value database, each item stored in the database is uniquely identified by a key that maps to a value. The value can be any type of object such as string, JSON object, image etc. Unlike relational databases which are structured and require fixed set of columns and rows, Key-value database does not have any predefined schema. This provides more flexibility in terms of storage and retrieval of data as it does not require any predefined structure for it to work correctly. The picture below is a representation of key-value data model:
For the NoSQL database based on KV data model, the data associated with the key is typically opaque to the database engine.
Key-value databases are suitable for use cases where the retrieval time is very important since they are designed to reduce delay during query processing. They are very efficient in handling high volumes of read/write operations with low latency due to their simple design structure which allows only single operation on each key at a given time.
A great example of key-value data models in the real world can be found in online retail stores. Many retailers store user accounts and their associated information as key-value pairs within their NoSQL databases. For example, when a customer creates an account on an online store, they enter their name and address details into the account registration form. This information is stored within the store’s NoSQL database as key-value pairs; there will be a unique customer identifier which is used to access all the other associated information such as name, address, etc. When customers log into the site again, they are able to retrieve their personal details through this identifier.
Another real world application where you can find examples of NoSQL key-value models being used is web caching technology. Web caches store web page documents on whatever device requested them previously so that if another request comes in from the same device (or IP address), it can serve up that document much more quickly than having to re-download it from its origin server again – thus saving bandwidth costs while still ensuring faster response times to users’ requests.
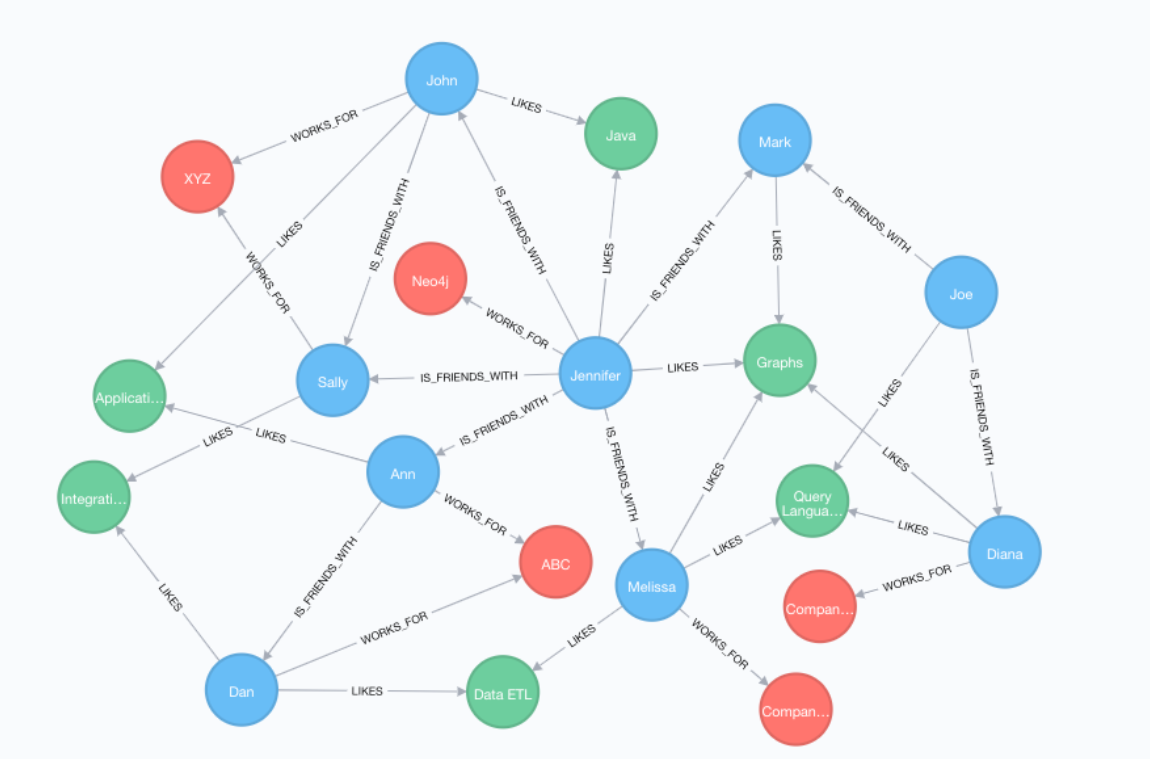
Graph data model for NoSQL databases is a way of representing the relationships between objects in a database. It uses nodes and edges to define the relationships between objects, providing flexibility and scalability for complex datasets. Graph databases such as Neo4j and Amazon Neptune are particularly well suited to applications that require analyzing complicated interconnections, as they can quickly traverse networks of related data. The following is a representation of graph data model:
Nodes represent entities in the graph – such as people, places, or events – while edges represent their relationships. A node may have multiple properties associated with it, such as name, age, address, or occupation. Edges can also be given properties — like “likes” or “dislikes”— which can be used to store additional information about the relationship between two nodes. In a graph database structure, relationships are stored in their own collection alongside other information about each node; this eliminates duplication and allows faster query performance than more traditional relational databases.
Apart from storing data about individual objects and their relations to one another, graph databases are capable of performing complex traversals across data sets—for example, when looking for paths from one node to another—without needing large numbers of joins or other time-consuming operations performed by a relational database engine. This makes them ideal for applications such as recommendation systems or fraud detection where there are many interconnected elements that need to be considered when making decisions or predictions.
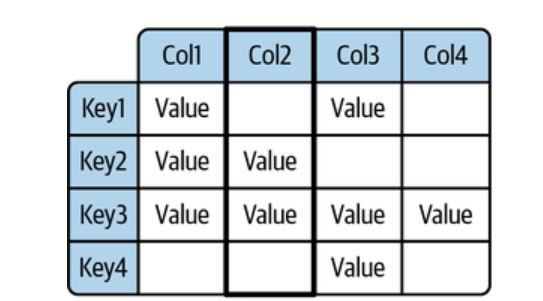
Column family data model is the representation of the data in a wide column model, allowing columns within a row to be uniquely identified and sorted. It is an enhanced version of traditional key-value (KV) stores, providing more flexibility in terms of the kinds of data that can be stored. Unlike relational databases, which have fixed tables with predefined columns, column family databases such as Apache Cassandra and Google Bigtable allow for dynamic columns and do not require predetermined schemas. This makes them ideal for unstructured or semi-structured data that does not fit neatly into traditional table structures. The following is a representation of wide column data model:
Wide column or column family data model can be understood as a two-dimensional hash map which enable columns within a row to be uniquely identified and sorted using the column name. Similar to a document database, each row in a collection can have different columns. are examples of wide column databases.
NoSQL data models provide organizations with powerful tools that allow them to effectively manage large volumes of unstructured or semi-structured data while still providing fast retrieval times and high levels of scalability compared to traditional relational SQL databases . With so many different types available there’s boundless potential for what you can do with your data whether it’s powering analytics operations or providing users with better experiences on your website or application . The sky’s the limit!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}