Following are the key problems related with learning algorithm that are described later in this article:
The challenge is to identify whether the learning algorithm is having one of the following:
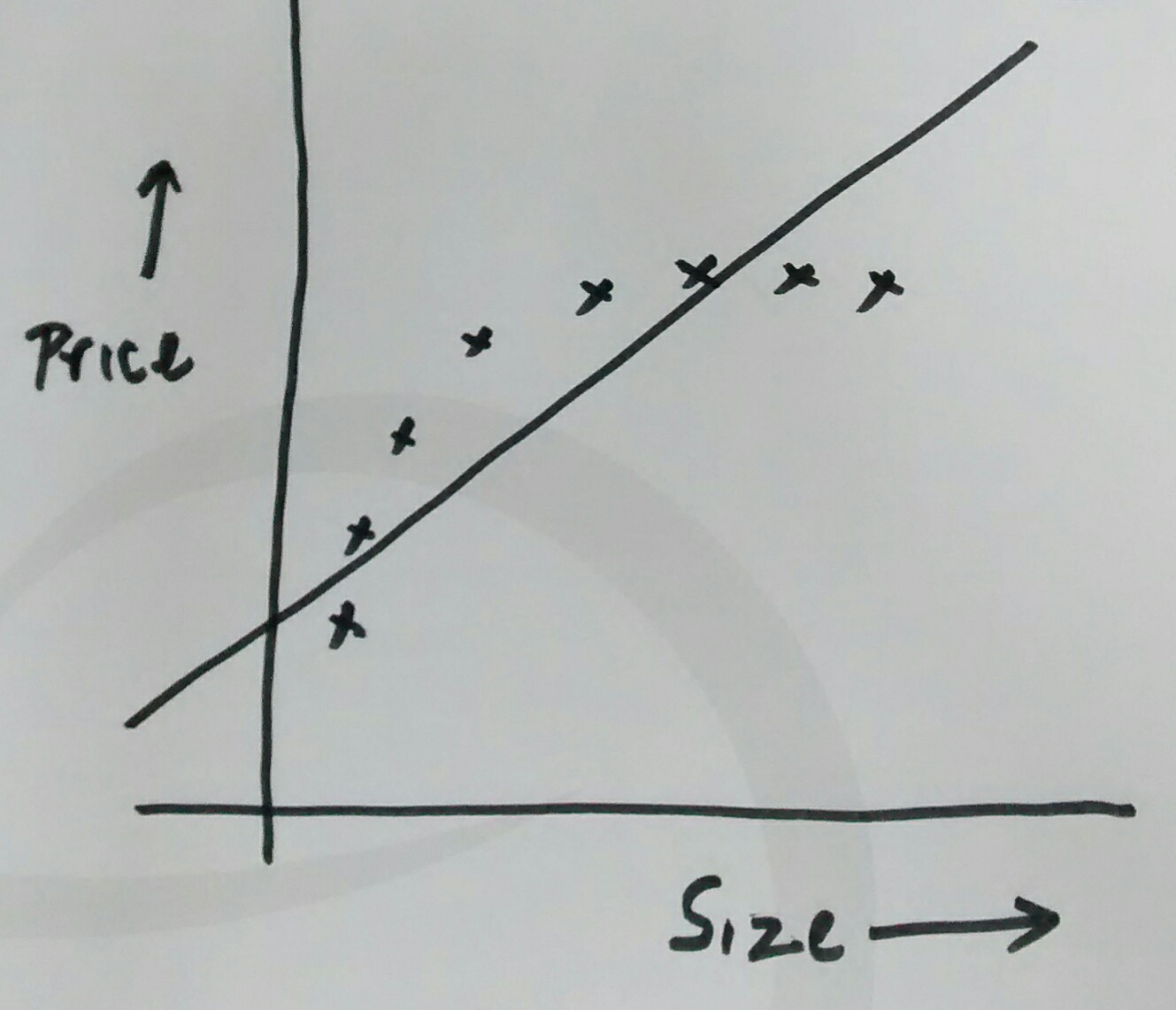
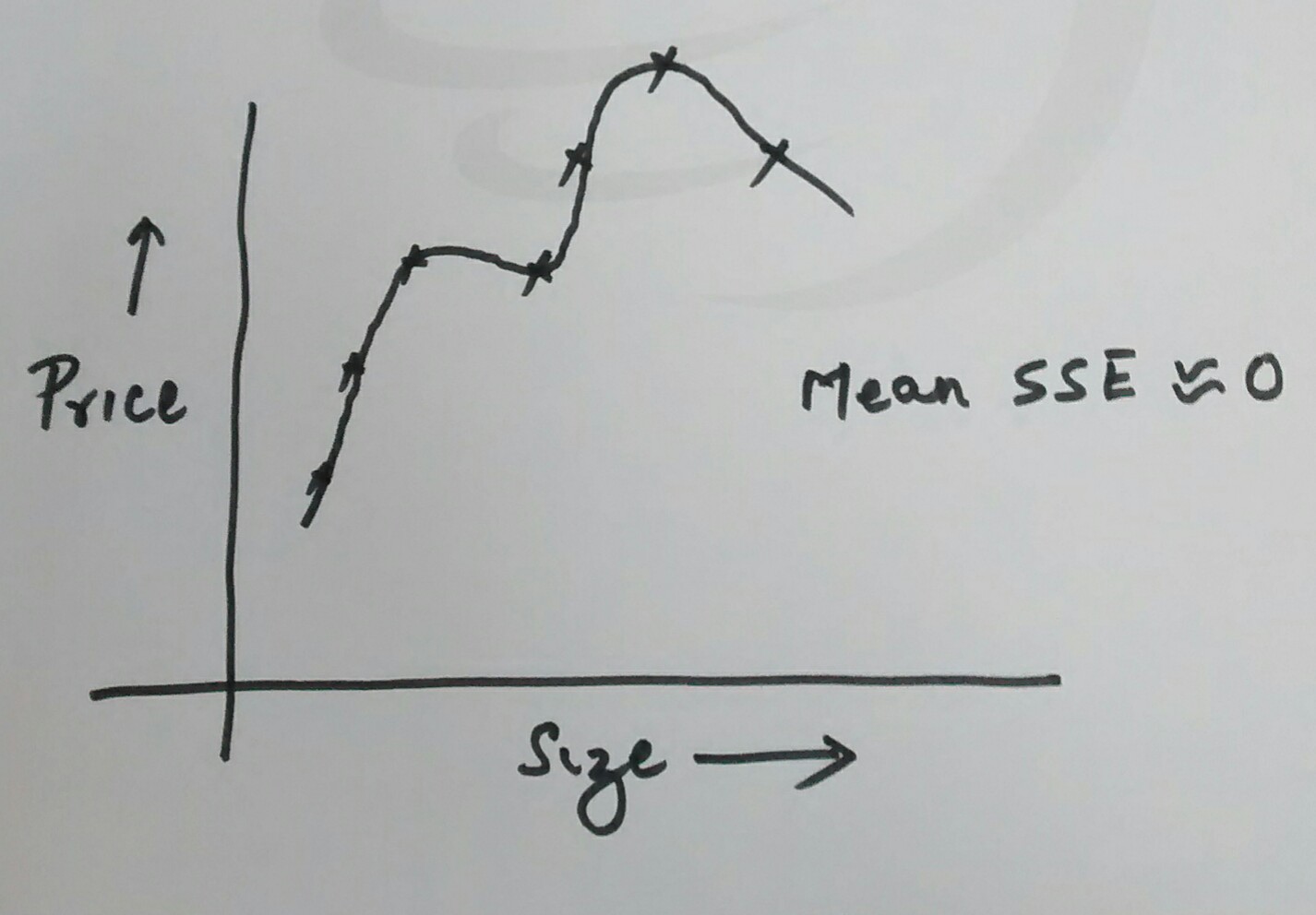
Following technique can be used to identify the case of high bias (under-fitting) or high variance (over-fitting) given that the data set is split into training, cross-validation set and test set and, training dataset is used to determine the parameters that makes the best fit (least error value).
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}