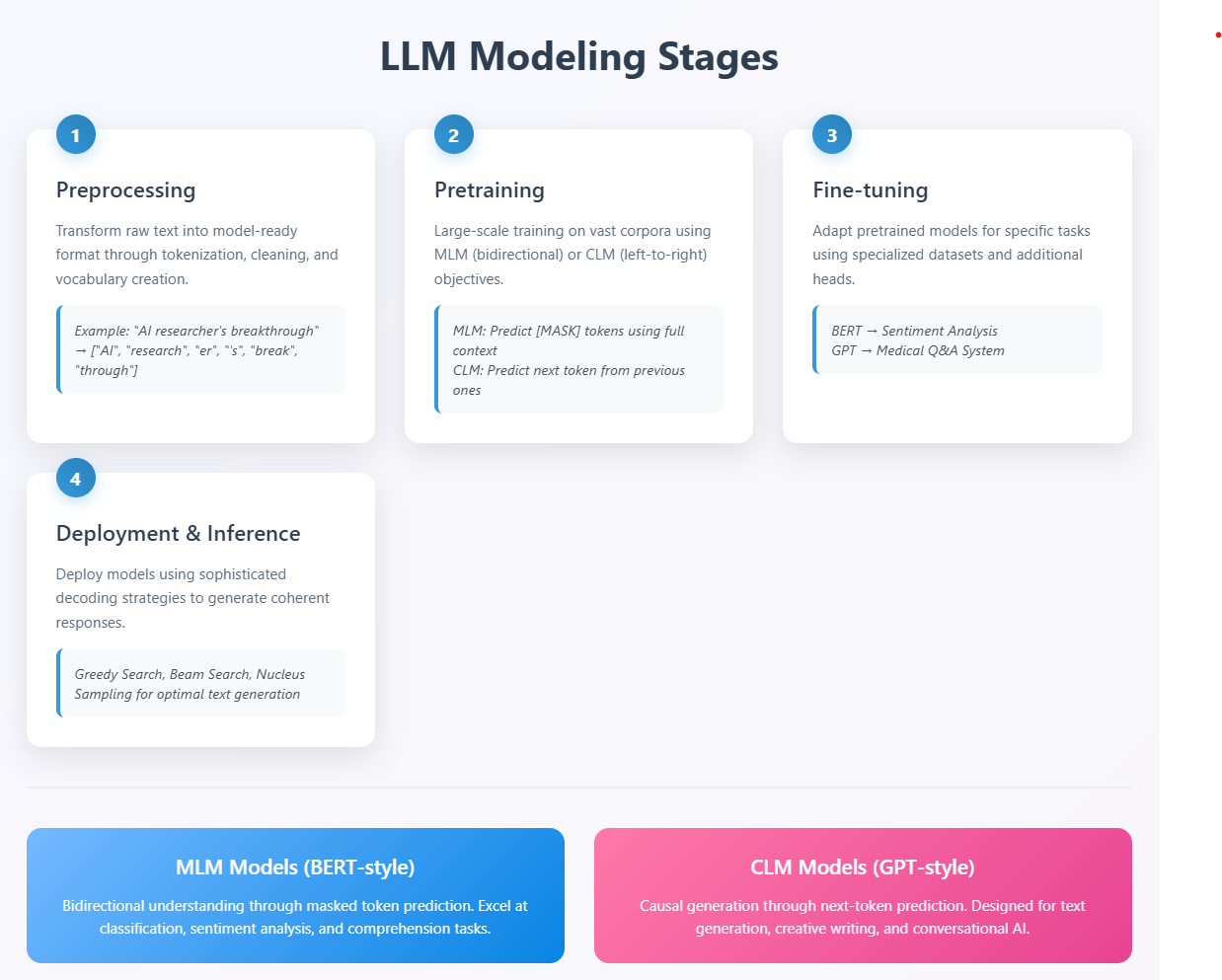
Stage 1: Preprocessing – Laying the Foundation
The preprocessing stage involves transforming raw text data into a format suitable for model training. This includes segmenting the raw text into manageable units and tokenizing it using algorithms like BPE (Byte-Pair Encoding) to create individual tokens from a predefined vocabulary. For example, the sentence “The AI researcher’s breakthrough was unexpected” might be tokenized into [“The”, “AI”, “research”, “er”, “‘s”, “break”, “through”, “was”, “un”, “expected”], where common subwords like “er”, “through”, and “un” are recognized as separate tokens. The stage also encompasses data cleaning tasks such as removing HTML tags, normalizing Unicode characters, handling special symbols, and filtering out inappropriate content to ensure the text corpus is ready for model consumption.
This foundational step is crucial because it determines how the model will “see” and process language, making the difference between a model that understands context and one that struggles with basic comprehension.
Stage 2: Pretraining – Building Language Understanding
During pretraining, models undergo large-scale training on vast text corpora using either MLM (Masked Language Modeling) or CLM (Causal Language Modeling) objectives. MLM, used by BERT-style models, randomly masks tokens in a sentence and trains the model to predict the missing words using bidirectional context from both left and right sides. CLM, used by GPT-style models, trains the model to predict the next token in a sequence using only the preceding tokens in a left-to-right manner. This stage enables the model to capture semantic patterns and develop linguistic structure understanding from natural language, ultimately creating a foundation model with general language capabilities that can be adapted for various downstream tasks.
Think of this stage as teaching the model the fundamental rules of language – grammar, semantics, and context – by exposing it to billions of words from books, articles, and web content.
Stage 3: Fine-tuning – Specializing for Specific Tasks
The fine-tuning stage adapts the pretrained model for specific tasks through training on smaller, specialized datasets, often requiring only a few epochs. For example, a pretrained BERT model with general language understanding can be fine-tuned for sentiment analysis by adding a classification head and training on movie review datasets where inputs like “This film was absolutely terrible and boring” are paired with negative labels, while “An incredible masterpiece with outstanding performances” receives positive labels. Similarly, a pretrained GPT model can be fine-tuned for medical question-answering by training on doctor-patient dialogue datasets, enabling it to provide more accurate and domain-specific responses. This process involves integrating additional model heads when needed and focuses on domain adaptation to optimize performance for target use cases while leveraging the general knowledge acquired during pretraining.
This is where general-purpose language models become specialists, learning to excel at specific tasks while retaining their foundational language understanding.
Stage 4: Deployment & Inference – Bringing Models to Life
In the final stage, models are deployed in production environments to execute downstream tasks in real-world scenarios. The inference process involves the model outputting probability scores for every token in its vocabulary, creating a probability distribution that indicates how likely each possible next token is given the current context. To convert these probabilities into actual text output, various decoding strategies are employed: greedy search selects the highest probability token at each step for fast but potentially repetitive results; beam search maintains multiple candidate sequences simultaneously and explores several high-probability paths to find more optimal overall sequences; and nucleus sampling introduces controlled randomness by sampling from only the most probable tokens (top-p) to generate more diverse and creative outputs while maintaining coherence. For causal LLMs, this occurs through autoregressive generation in a token-by-token manner to produce contextually coherent responses to user prompts.
This stage is where the magic happens – where probability distributions become coherent, helpful text that users can interact with in real-time.
The Complete Picture
The four-stage modeling process creates two distinct families of language models, each optimized for different purposes. MLM-based models like BERT excel at understanding tasks through their bidirectional training approach—they learn to predict masked tokens using context from both directions, making them powerful for classification, sentiment analysis, and question answering. These encoder-only models typically undergo preprocessing, MLM pretraining on large corpora, task-specific fine-tuning with classification heads, and deployment for discriminative tasks.
CLM-based models like GPT follow a different path, maintaining consistency by using the same causal language modeling objective throughout both pretraining and fine-tuning stages, differing only in the corpora used. Their left-to-right token prediction training makes them naturally suited for text generation, where sophisticated decoding strategies—greedy search, beam search, and nucleus sampling—transform probability distributions into coherent, contextually relevant responses.
Understanding these parallel paths helps explain why architectural decisions matter more than raw model size, and why choosing between encoder-only understanding models and decoder-only generation models depends fundamentally on your intended application rather than simply picking the largest available model.
Whether you’re a researcher, developer, or simply curious about AI, recognizing these stages and architectural differences provides valuable insight into the remarkable journey from raw text to intelligent conversation, and why the “bigger is better” assumption doesn’t always hold true in practical applications. Check out the mention of these modeling stages in this paper – Advancing Transformer Architecture in Long Context LLMs: A Comprehensive Survey
{kind=link}