Last updated: 16th August, 2024
Gradient Boosting Machines (GBM) Algorithm is considered as one of the most powerful ensemble machine learning algorithms used for both regression and classification problems. This algorithm has been proven to increase the accuracy of predictions and is found to be extremely popular among data scientists. Let’s take a closer look at GBM and explore how it works with an example.
Gradient boosting algorithm is an ensemble machine learning technique in which an ensemble of weak learners are created. In simpler words, the algorithm combines several smaller, simpler models in order to obtain a more accurate prediction than what an individual model would produce. Models that use gradient boosting techniques for training purpose are called gradient boosting machines (GBMs). Most GBMs use decision trees and are also called gradient boosting decision trees (GBDTs). Like random forests, GBDTs make predictions by combining the output of decision trees. But rather than build independent decision trees from random subsets of the data, GBDTs build dependent decision trees, one after another, training each using output from the last. The first decision tree models the dataset. The second decision tree models the error in the output from the first, the third models the error in the output from the second, and so on. To make a prediction, a GBDT runs the input through each decision tree and sums all the outputs to arrive at a result.
In GBDT models, each decision tree is a weak learner. GBDTs typically use decision tree stumps, which are decision trees with depth 1 (a root node and two child nodes). During training, the first step is taking the mean of all the target values in the training data to create a baseline for predictions. Then this mean is subtracted from the target values to generate a new set of target values or residuals for the first tree to predict. After training the first tree, the input is run through this tree to generate a set of predictions. Then these predictions are added to the previous set of predictions and a new set of residuals are generated by subtracting the sum from the original (actual) target values. The second tree is then trained to predict those residuals. This process is is repeated for n trees, where n is typically 100 or more. This results in creation of an ensemble model. To help ensure that each decision tree is a weak learner, GBDT models multiply the output from each decision tree by a learning rate to reduce their influence on the outcome. The learning rate is usually a small number such as 0.1 and is a parameter that can be specified when using classes that implement GBMs.
The above process is represented in the following diagram:
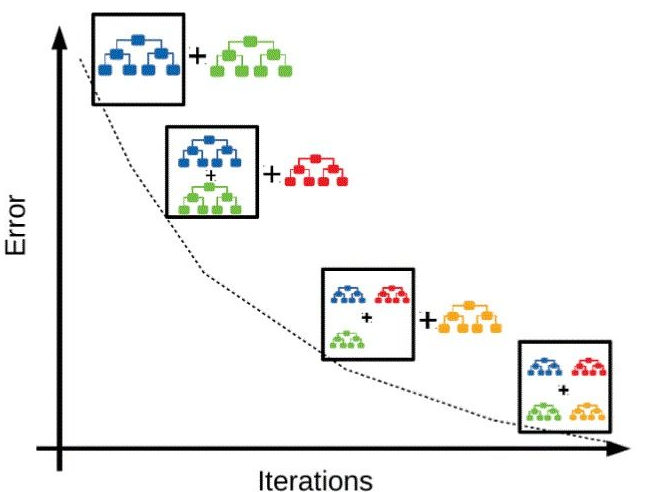
The picture below represents how error reduces as the training progresses based on week learners.
Let’s say we have a dataset containing information about customers and their spending habits over time. We want to use the gradient boosting algorithm to predict how much money each customer will spend next month based on this data. To do this, we will start by creating a baseline prediction using a simple regression model such as linear regression. We can then add additional weak learners such as decision trees or random forests which will help us refine our predictions and increase accuracy levels even further. As we continue adding more weak learners, our model should become more accurate until it reaches its maximum potential accuracy level or until no further improvement can be made with additional weak learners.
While gradient boosting at its most basic level can be applied to help optimize a wide array of tasks, there are several notable cases of gradient boosting in the real world that have been successful. One example is gradient boosted trees, which can be used as an efficient method for solving complex problems such as weather prediction or medical diagnosis. Other examples include gradient boosted decision tree learning (GBDT) for detecting fraudulent credit card transactions and gradient boosting machines for facial recognition systems. The ability of gradient boosting algorithms to find unique combinations of linear models has also proven useful for predicting stock market trends. All these real-world uses demonstrate that gradient boosting can be a powerful tool for solving intricate problems and enhancing predictive accuracy.
Gradient boosting is used in marketing to optimize budget allocation across channels so as to maximize the return on investments (ROI). Additionally, gradient boosting algorithms have applications in search ranking studies, such as finding the most relevant documents from an extensive list of options. Gradient boosting has also been utilized in medical diagnoses, such as predicting the risk of cancer relapse and Heart Attack prediction. Other examples include fraud detection for loan applicants and churn analysis for customer retention initiatives. As evidenced by these real-world applications, gradient boosting algorithms are invaluable tools for accurate predictions and analytics.
In conclusion, gradient boosting algorithm are powerful tools for making accurate predictions from data sets and have been proven effective in many applications. By combining multiple weak learners into one strong model, GBAs are able to reach high levels of accuracy for any given task. By understanding how GBAs work and utilizing them effectively, you can gain valuable insight from your data sets and make better decisions based on your findings!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}