Have you ever wondered how you might determine the relationship between two sets of data that aren’t necessarily linear, or perhaps don’t adhere to the assumptions of other correlation measures? Enter the Spearman Rank Correlation Coefficient, a non-parametric statistic that offers robust insights into the monotonic relationship between two variables – perfect for dealing with ranked variables or exploring potential relationships in a new, exploratory dataset.
In this blog post, we will learn the concepts of Spearman correlation coefficient with the help of Python code examples. Understanding the concept can prove to be very helpful for data scientists. Whether you’re exploring associations in marketing data, results from a customer satisfaction survey, or anything in between, the Spearman correlation could be the key to unlocking the insights you need.
The Spearman’s rank correlation coefficient, commonly referred to as Spearman’s rho, is a statistical measure of the strength and direction of the monotonic relationship between two ranked variables.
The Spearman Rank Correlation Coefficient, denoted as ρ (rho), is a non-parametric measure of statistical dependence between two variables. It assesses how well the relationship between two variables can be described using a monotonic function. In simpler terms, it measures the strength and direction of association between two ranked variables.
The following is the interpretation of value of Spearman coefficient:
Let’s illustrate this concept with an example.
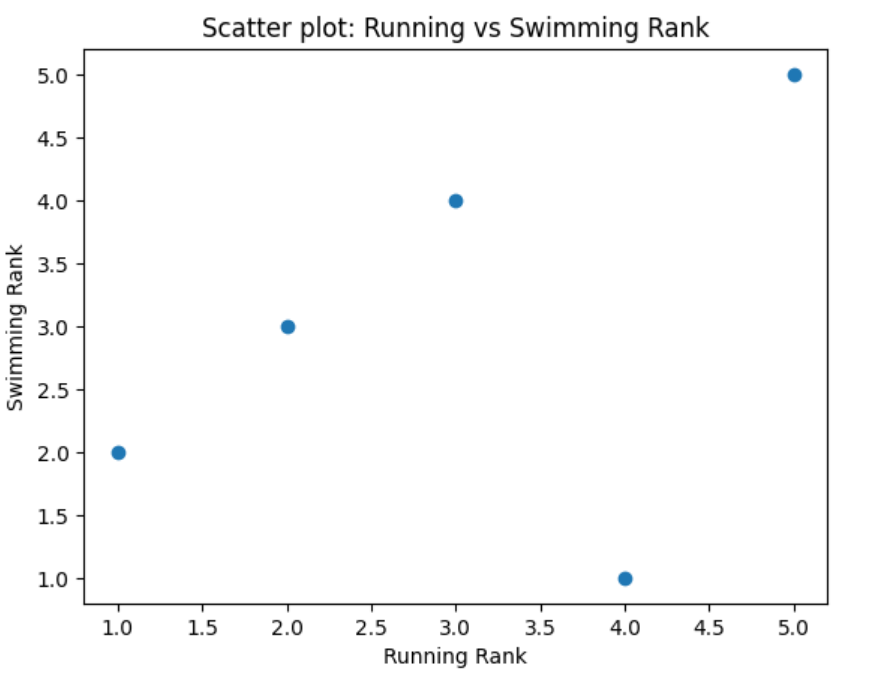
Suppose we have a small group of five friends who took part in a 5km running race and a swimming race. We can rank their performance in both events from 1 (best) to 5 (worst):
| Friend | Running Race Rank | Swimming Race Rank |
|---|---|---|
| A | 1 | 2 |
| B | 2 | 3 |
| C | 3 | 4 |
| D | 4 | 1 |
| E | 5 | 5 |
Now, we want to understand the correlation between their performances in the two races. Here, we can use the Spearman correlation coefficient.
To calculate the coefficient, we use the formula:
ρ = 1 – ( (6 * Σd²) / (n * (n² – 1)) )
Where:
First, calculate the difference in ranks (d), square it (d²), and sum all the squared differences (Σd²).
| Friend | Running Rank (R1) | Swimming Rank (R2) | d = R1 – R2 | d² |
|---|---|---|---|---|
| A | 1 | 2 | -1 | 1 |
| B | 2 | 3 | -1 | 1 |
| C | 3 | 4 | -1 | 1 |
| D | 4 | 1 | 3 | 9 |
| E | 5 | 5 | 0 | 0 |
Σd² = 1 + 1 + 1 + 9 + 0 = 12
Now, substitute Σd² and n in the formula:
ρ = 1 – ( (6 * Σd²) / (n * (n² – 1)) )
ρ = 1 – ( (6 * 12) / (5 * (5² – 1)) )
ρ = 1 – (72 / 120)
ρ = 1 – 0.6
ρ = 0.4
So, the Spearman correlation coefficient of the friends’ ranks in the races is 0.4, indicating a moderate positive correlation.
Remember, the value of ρ ranges from -1 to 1. A positive ρ indicates a positive correlation (as one variable increases, the other tends to increase), and a negative ρ indicates a negative correlation (as one variable increases, the other tends to decrease). A value close to 0 indicates no correlation.
The Spearman correlation coefficient is a non-parametric measure that’s useful in a variety of real-life scenarios. Here are a few examples:
Spearman correlation is most useful when the data are ranks or when you don’t want to make any assumptions about a linear relationship or normal distribution for the available data.
The following represents a simple Python code snippet using the scipy library’s spearmanr function, which calculates the Spearman rank correlation coefficient. The data from previous example is used. The method spearmanr is invoked with the two lists of ranks as arguments. The method returns the correlation coefficient and the p-value. We’re only interested in the coefficient, so we ignore the p-value by assigning it to _.
from scipy.stats import spearmanr
# Ranks of friends in running and swimming
running_rank = [1, 2, 3, 4, 5]
swimming_rank = [2, 3, 4, 1, 5]
# Calculate Spearman's correlation
spearman_corr, _ = spearmanr(running_rank, swimming_rank)
print(f"Spearman's correlation coefficient is: {spearman_corr}")
The correlation can also be seen as the following scatter plot:
The following represents some of the key differences between Spearman rank correlation coefficient and Pearson correlation coefficient:
| . | Pearson Correlation Coefficient | Spearman Correlation Coefficient |
|---|---|---|
| Type of Data | Continuous, interval or ratio data, assumed to be normally distributed | Ordinal, interval, or ratio data; does not require a normal distribution |
| Assumptions | Assumes linearity and homoscedasticity (equal variance) in the data | No assumptions about the distribution and can handle non-linear relationships |
| Measures | Linear relationships | Monotonic (increasing or decreasing, but not necessarily at a constant rate) relationships |
| Calculation | Based on actual data values and their means | Based on data ranks |
| Appropriate Usage | When both variables are normally distributed and the relationship is linear | When data does not meet the assumption of normality or the relationship is non-linear |
The Spearman Rank Correlation Coefficient is a non-parametric measure that quantifies the degree of association between two ranked variables. This robust statistical tool provides an understanding of the monotonic relationship between these variables, allowing us to assess how well the relationship can be described using a monotonic function. Whether your data are ordinal or contain outliers, Spearman’s rank correlation has proven to be an effective measure, helping to glean insights from data that other correlation measures might miss.
The need for Spearman’s correlation arises primarily when dealing with non-linear relationships or when the data do not meet the assumptions required for Pearson’s correlation coefficient. This brings us to one of the key differences between the two: while Pearson’s correlation works with the actual data values and is most effective in determining linear relationships, Spearman’s correlation operates on the rank of data and efficiently uncovers monotonic relationships, whether linear or not.
If you would like to know about greater details, please feel free to reach out.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}