In the dynamic realm of AI, where labeled data is often scarce and costly, self-supervised learning helps unlock new machine learning use cases by harnessing the inherent structure of data for enhanced understanding without reliance on extensive labeled datasets as in the case of supervised learning. Simply speaking, self-supervised learning, at its core, is about teaching models to learn from the data itself, turning unlabeled data into a rich source of learning. There are two distinct methodologies used in self-supervised learning. They are the self-prediction method and contrastive learning method. In this blog, we will learn about their concepts and differences with the help of examples.
What is the Self-Prediction Method of Self-Supervised Learning?
In self-prediction, some parts of the input data are changed or hidden and the model is trained to reconstruct the original inputs. Let’s understand how it relates to self-supervised learning.
Starting with raw data: Imagine you have a collection of images but no labels or annotations describing those images. Your goal is to learn useful features or representations from these images without any explicit guidance.
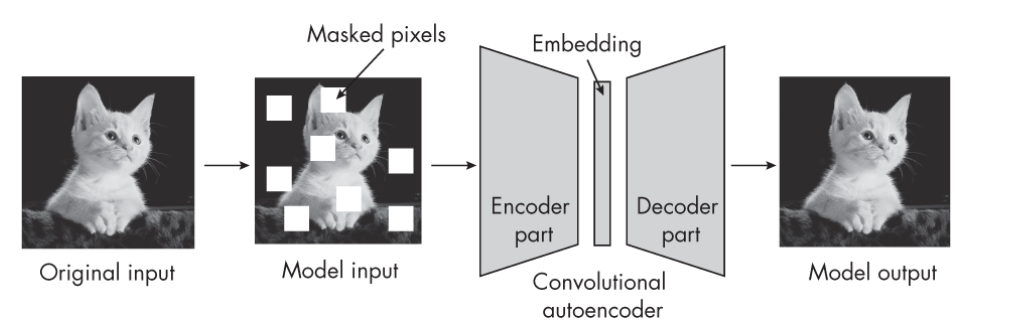
Creating a learning task: To teach your model something useful about the data, we artificially create a task. We do this by modifying the original images in some way and then asking the model to predict the original, unaltered image. For example, we might hide parts of an image (such as by applying a mask that covers a portion of the image) and then train your model to fill in the missing parts.
Learning by prediction: The process of trying to reconstruct the original images forces the model to learn about the underlying structure of the data. To successfully predict the missing parts, the model needs to understand context, shapes, textures, and possibly even higher-level concepts like objects and their interactions within the image. These are the kinds of features that are useful for a wide range of tasks, even though the model wasn’t trained for any specific task to begin with.
Self-supervision through self-prediction: In this scenario, the “label” for each training example is part of the input data itself. The model uses the visible parts of an image to predict the hidden parts. This self-generated labelprovides a form of supervision that guides the learning process, hence the term “self-supervised learning.”
The following is a classic example of a masked autoencoder used for a self-prediction task. The masked autoencoder is trained to reconstruct the masked image and that in turns learns about context, shapes, textures, etc about the object. Read more about the topic in the book “Machine Learning Q & AI” by Sebastian Raschka.
What is the Contrastive Learning Method?
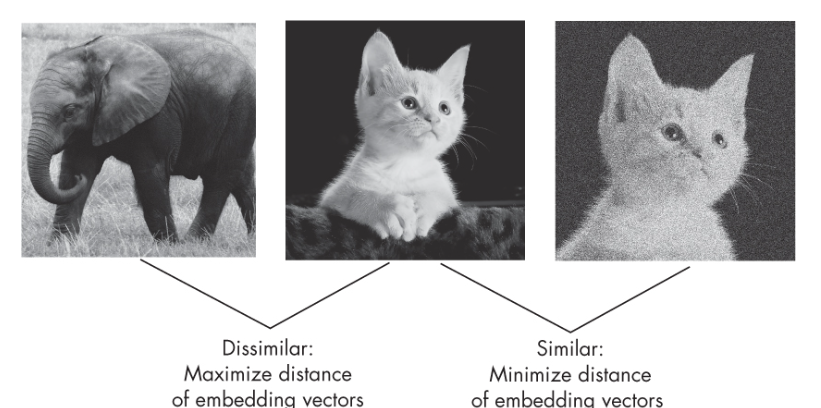
Contrastive learning is a powerful technique in the toolbox of self-supervised learning, leveraging the idea that a model can learn useful representations by comparing different pieces of data. In contrastive learning, neural networks are trained to learn an embedding space where similar inputs are grouped and dissimilar ones are placed far apart. In essence, the network learns to cluster embeddings of similar inputs close to each other in the embedding space, much like you grouping people from the same family in your mental map. For example, for images, similar inputs could be different pictures of the same object or scene, and dissimilar inputs could be pictures of entirely different objects or scenes. The picture below represents the same.
The supervision comes from the data itself—specifically, the relationships between different pieces of data. The model doesn’t need external labels to learn meaningful representations; instead, it learns by understanding the concept of similarity and dissimilarity within the data. This is self-supervised learning because the model generates its supervision based on the task of contrasting positive pairs against negative pairs.
Contrastive learning can be categorized into two classes – sample contrastive learning and dimension contrastive learning. This topic will be discussed in a future blog.
Differences between Self-Prediction & Contrastive Learning
The self-prediction and contrastive methods represent two distinct approaches to self-supervised learning, each leveraging different strategies to learn from unlabeled data. Here are the key differences between them:
Objective Focus
Self-Prediction: Focuses on reconstructing the original input from a corrupted or partial version of itself. The model learns by predicting the missing or altered parts of the input data.
Contrastive Learning: Focuses on learning to distinguish between similar (positive) and dissimilar (negative) pairs of inputs. The model learns by pulling embeddings of similar items closer and pushing dissimilar items apart in the embedding space.
Data Manipulation
Self-Prediction: Involves altering or hiding parts of the input data and asking the model to predict these hidden parts. The manipulation is internal to individual data points (e.g., masking parts of an image).
Contrastive Learning: Involves comparing different but related data points. The method relies on creating pairs or groups of inputs (both similar and dissimilar) without altering the data points themselves.
Learning Mechanism
Self-Prediction: Encourages the model to understand the internal structure of the data to fill in the gaps. This method inherently teaches the model about the continuity and context within individual data points.
Contrastive Learning: Teaches the model about the relationships between different data points. It encourages the model to learn an abstract representation that encapsulates the notion of similarity and dissimilarity among data points.
Representation Learning
Self-Prediction: Leads to learning representations based on the context within individual data points, potentially focusing on local features or patterns necessary for reconstruction.
Contrastive Learning: Aims to learn global representations that capture the essence of what makes data points similar or different, often leading to more generalized features that are useful across a variety of tasks.
Application Suitability
Self-Prediction: Particularly effective in tasks where understanding the detailed structure or content of individual data points is crucial, such as in image restoration, denoising, or inpainting.
Contrastive Learning: Especially beneficial in scenarios where distinguishing between categories or types of data points is essential, making it ideal for tasks like clustering, anomaly detection, and fine-grained classification.
Example Use Cases
Self-Prediction: Could be used in autoencoders for dimensionality reduction, in image completion, or in next-word prediction tasks in language models.
Contrastive Learning: Often used in tasks like face recognition, where distinguishing between individuals is key, or in unsupervised pre-training for downstream classification tasks.
I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin. Check out my books titled as Designing Decisions, and First Principles Thinking.
I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning and BI. I would love to connect with you on Linkedin. Check out my books titled as Designing Decisions, and First Principles Thinking.
{kind=link}
{kind=link}