Last updated: 16th Sep, 2024
Recommender systems are widely used in applications such as personalized content recommendation (e.g., movies, books, music), online shopping, and social media. One common example of a recommender system is Netflix. Netflix uses a sophisticated recommender system to suggest movies and TV shows that a user may want to watch. The recommendation algorithm takes into account past user behavior, such as ratings, viewing history, and interactions with content (e.g., likes, watch time).
Recommender systems typically leverage techniques such as collaborative filtering, content-based filtering, or hybrid methods that combine both approaches. These systems analyze patterns in user behavior, item attributes, and sometimes additional context, such as demographics or social network data, to provide tailored suggestions and improve user experience.
In this blog post, you will learn about recommender systems and some of the different types of recommender systems with the help of examples.
A recommender system are systems that recommend products or services to customers. Amazon’s recommender system reportedly drives 35% of its sales (2020 data). Recommender systems get utilized in a variety of areas, with commonly recognized examples taking the form of playlist generators for video and music services, product recommenders for online stores, etc.
Recommender systems often leverage machine learning (ML) algorithms in order to make better predictions about a user’s preferences. These ML algorithms has its own strengths and weaknesses, and the best algorithm for a particular application will depend on the nature of the data. The following are some of the ML algorithms that are used in recommender systems:
The following is a list of benefits / value of building recommender system and why businesses must consider:
There are a number of different types of recommender systems. Some of them are listed below:
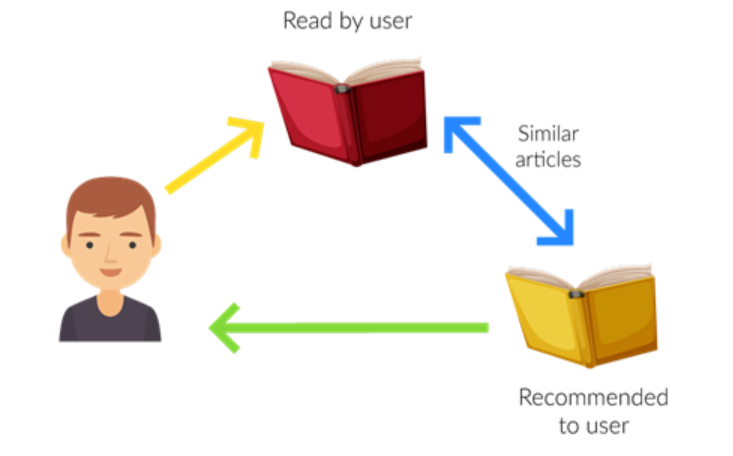
The most common type of recommender system is the content-based recommender system. A content-based recommender system is a type of recommender system that relies on the similarity between items to make recommendations. For example, if you’re looking for a new movie to watch, a content-based recommender system might recommend movies that are similar to ones you’ve watched in the past. The picture below represents content-based filtering recommender system:
Content-based recommender systems are commonly used in music, books, and movies. They can be used to recommend products, services, or even websites. Content-based recommender systems are based on the idea that if you like one item, you’re likely to like other items that are similar to it.
To build a content-based recommender system, you need to first define what similarity means. This is where machine learning comes in. Content-based recommenders require two ingredients: a way to vectorize – convert to numbers – the attributes that characterize a service or product, and a means for calculating similarity between the resulting vectors. The first one can be achived by using using classes such as sklearn CountVectorizer to converts text into tables of word counts. For similarity, one of the simplest and most effective ways is a technique called cosine similarity. Cosine similarity isn’t limited to two dimensions; it works in higher-dimensional space as well. To help compute cosine similarities regardless of the number of dimensions, Scikit offers the cosine similarity function.
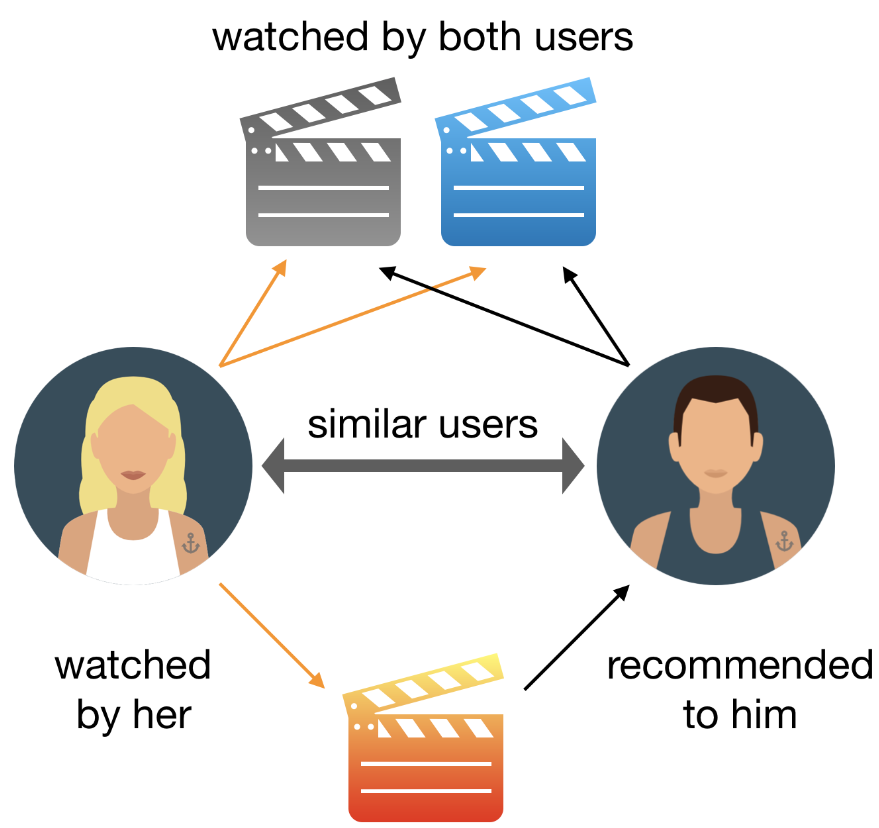
Another type of recommender system is the collaborative filtering recommender system. A collaborative filtering recommender system is a type of machine learning algorithm that makes predictions about what a user might want to buy or watch based on the past behavior of other users. The algorithm looks at the items that other users with similar taste have purchased or rated highly, and recommends those items to the new user. The picture below represents collaborative-filtering recommender system:
The main advantage of collaborative filtering is that it doesn’t require any information about the users or items; all it needs is a dataset of past user behavior. Collaborative filtering is one of the most popular techniques for building recommender systems, and is used by major companies such as Amazon, Netflix, and Spotify.
A third type of recommender system is the hybrid recommender system. The hybrid approach has become increasingly popular in recent years as it offers the potential to overcome some of the limitations of each individual approach.
Content-based recommender systems focus on the attributes of items in order to make recommendations. This can often lead to issues with scalability, as the system needs to be constantly updated with new content in order to make accurate recommendations. Collaborative filtering systems, on the other hand, focus on the relationships between users and items. This can often result in problems with sparsity, as it can be difficult to find enough users who have rated a given item. The hybrid approach seeks to overcome these limitations by combining the two approaches.
A hybrid recommender system is a type of recommender system that combines both content-based and collaborative filtering approaches. The hybrid approach takes advantage of both content-based and collaborative filtering by using them to supplement each other. For example, a hybrid recommender system might first identify a set of items that are similar to the item the user is interested in, and then use collaborative filtering to identify which of those items the user is most likely to enjoy. This approach can provide more accurate recommendations than either method used alone. The hybrid approach has been shown to be more effective than either method used alone, as it is able to leverage the strengths of both approaches. Hybrid recommender systems are often more scalable and efficient than pure content-based or collaborative filtering systems.
Some of the most popular examples of recommender systems include the ones used by Amazon, Netflix, and Spotify.
Recommender systems are a type of machine learning based systems that are used to predict the ratings or preferences of items for a given user. There are three main types of Recommender Systems: collaborative filtering, content-based, and hybrid. Some of the most popular examples of Recommender Systems include the ones used by Amazon, Netflix, and Spotify. Collaborative filtering systems use past user behavior to make recommendations for new products. Content-based systems focus on the attributes of items in order to make recommendations. The hybrid approach is a combination of both content-based and collaborative filtering approaches. Hybrid recommender systems are often more scalable and efficient than pure content-based or collaborative filtering systems. If you would like to learn more about Recommender Systems, there are many resources available online. Please let us know if you have any questions. Thank you for reading!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
View Comments
It was nice explanation. But can you list down problems which are faced by recommendation systems now these days?
thanks