Probability is a branch of mathematics that deals with the likelihood of an event occurring. It is important to understand probability concepts if you want to get good at data science and machine learning. In this blog post, we will discuss the basic concepts of probability and provide examples to help you understand it better. We will also introduce some common formulas associated with probability. So, let’s get started!
Probability is a concept in mathematics that measures the likelihood of an event occurring. It is typically expressed as a number between 0 and 1, with 0 indicating that an event is impossible and 1 indicating that an event is certain to occur or the event will always happen. The concept of probability can be used to model a variety of situations, from the roll of a dice to the probability of winning the lottery. Probability can be calculated using either theoretical or experimental methods. Theoretical probability is based on known rates and proportions, while experimental probability is based on actual data. Regardless of which method is used, probability can give us valuable insights into the likelihood of future events. Probability is an important tool for statisticians, mathematicians, scientists, and everyday people alike. By understanding probability, we can make better decisions, create more accurate predictions, and avoid potential pitfalls.
There are three types of probability:
Before getting into understanding concepts, formulas, let’s understand some basic terminologies used in the probability related problems:
Given the above terminologies, the probability of an event A (a subset of sample space S) can be expressed as the following:
P(A) = the number of ways event A can occur / the total number of possible outcomes in sample S
Thus, for an experiment representing single tossed dice, what is the probability that the even numbers show up?
The sample space = {1, 2, 3, 4, 5, 6}
Event, lets say A, that dice shows up even number = {2, 4, 6}
P(A) = 3 / 6 = 0.5
The probability P(A) can be understood as experimental probability going by the above three different types of probability.
The following are axioms of probability on which probability theory is based on:
From the above axioms, the following formula can be derived:
P(A∪B) = P(A)+P(B)-P(A∩B), where A and B are not mutually exclusive events
Given that events A & B represents events in the same sample space, union of A and B represents elements belonging to either A or B or both. P(A ∪ B) can be understood appropriately.
Marginal probability refers to the probability of an event occurring, without regard to any other events that may be occurring at the same time. For example, the marginal probability of flipping a coin and getting a head is 50%. Conditional probability, on the other hand, refers to the probability of an event occurring given that another event has already occurred. For example, the conditional probability of flipping a coin and getting a head given that the coin is fair is still 50%. These concepts are important because they help us to understand how different events are related to one another. In particular, they can help us to identify cause-and-effect relationships. For example, if we know that the marginal probability of a student getting a high grade on a test is low, but the conditional probability of a student getting a high grade on a test given that they studied is high, then we can conclude that studying is likely to be a causal factor in the outcome of the test.
The formula for the conditional probability of event A given event B has occurred is:
P(A|B) = P(A∩B)/P(B), where B is the event that has already occurred
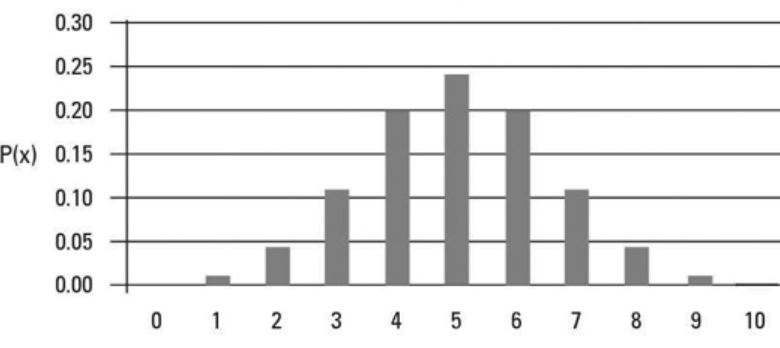
A probability distribution is a mathematical function that describes the likelihood of occurrence of different possible outcomes of a random variable. The probability of each possible outcome is represented by a range of values, called a probability distribution. Probability distributions are used to calculate the probability of various events, such as the likelihood of rolling a certain number on a dice. They can also be used to predict the probability of future events, such as the stock market. They are often represented using graphs, which makes it easy to visualize the probability of different outcomes. Probability distributions are important tools in statistics and are used in many different fields, from insurance to gambling. The picture below represents a sample of probability distribution.
There are two main types of probability distribution:
Probability is used in machine learning to create models that can predict future events. Probability can help to determine how likely it is that a certain event will occur, and this information can be used to make predictions about future events. For example, if a machine learning model is trained on a data set of historical weather patterns, it can use probability to make predictions about the likelihood of future weather events. Probability is also used in machine learning to assess the accuracy of models. By testing a model on a data set and evaluating the results, the researcher can determine how likely it is that the model will accurately predict future events. Probability can therefore be used to improve the accuracy of machine learning models and make more accurate predictions about future events.
Probability is a fundamental tool in machine learning, used for making predictions and decisions based on data. In supervised learning, the probability is used to estimate the likelihood of each possible outcome, based on known features. This can be used for classification tasks, such as predicting whether an email is a spam or not. In unsupervised learning, the probability is used to find patterns in data, such as clusters of similar items. Probability is also used in reinforcement learning, where an agent learns by trial and error to take actions that maximize a reward.
Bayesian machine learning is a probabilistic approach to machine learning that is based on Bayesian probability theory. Bayesian probability is an approach to the probability that uses prior beliefs about the likelihood of certain events to update the probability after new evidence is observed. This can be used for both supervised and unsupervised learning tasks. For example, in supervised learning, a Bayesian model can be used to estimate the probability of each possible outcome, based on known features. This can be used for classification tasks, such as predicting whether an email is a spam or not. In unsupervised learning, a Bayesian model can be used to find patterns in data, such as clusters of similar items.
Bayesian machine learning is a powerful tool for making predictions and decisions based on data. It is based on sound probability theory and can be used for both supervised and unsupervised learning tasks. If you are working with machine learning, then you should definitely consider using Bayesian machine learning in your work.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}