Paired sample t-tests are a commonly used statistical procedure used to compare two populations that are related in some way. They are often used for comparing dependent groups, such as the before and after results of an experiment. Data scientists must have a thorough understanding of the concept of paired sample t-test in order to craft accurate and reliable results when analyzing data. In this blog post, we will explore the formula, assumptions, and examples of paired sample t-tests.
Paired sample t-tests are used to test whether means of same or similar group different from each other under separate conditions (before and after intervention). For example, you would want to test the efficacy of a drug on the same group of patients before and after drug is given to the patients. When the goal is to assess the effect of a particular treatment before and after, you can use paired sample t-tests. Here are some real-world examples where paired sample t-test can be used:
Here is going to be the null and alternate hypothesis for paired sample t-tests:
The following represents the formula for T-statistics:
T = (mean difference between pairs) / (standard deviation of differences / square root of sample size)
Where:
Here is how the above would look like:
In the above formula, [latex]x_d[/latex] is the mean of difference in the change variable, [latex]s_d[/latex] is standard deviation of difference in change variable and n is the size of the sample.
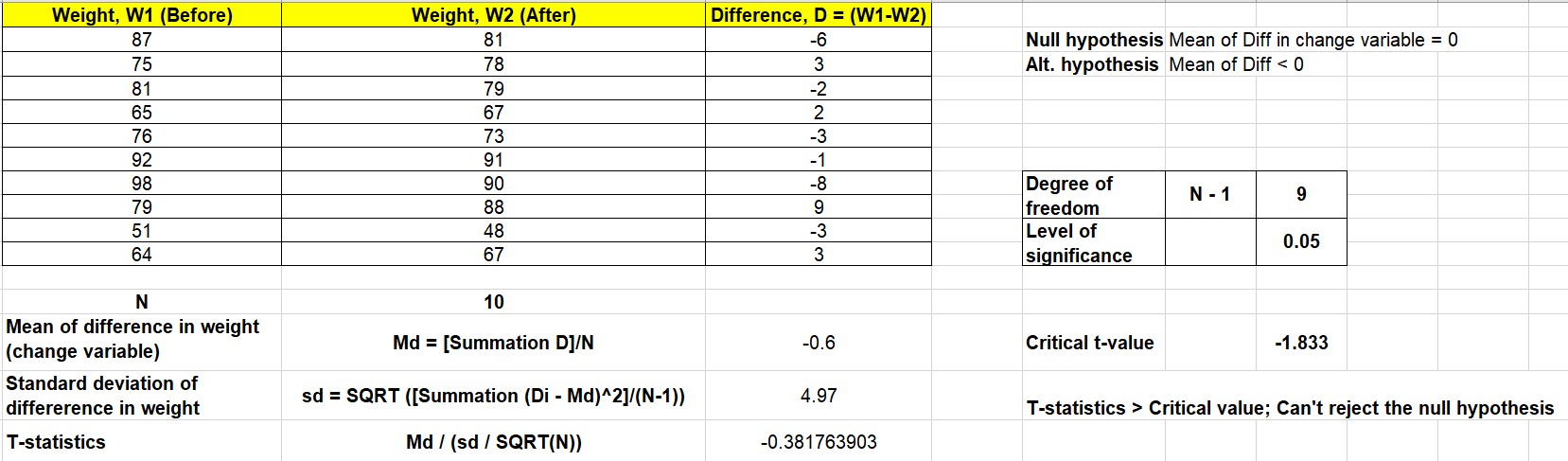
Based on the above formula, lets take a look at the example. Lets say the hypothesis is that walking for 1 hour a day for 3 months result in weight loss. In the example below, 10 people were subjected to the experiment and their weights (in KGs) were recorded after 3 months.
Null hypothesis is that the mean of difference between 10 pairs is zero. In other words, the change is weight is not significant.
Alternate hypothesis is that the mean of difference between 10 pairs is less than zero. In other words, the weights decrease after the walking is significant based on the evidence.
In the above test, the t-statistics is greater than critical t-value. In other words, it does not lie in the critical region. Thus, we don’t have enough evidence to reject the null hypothesis. So, based on the evidence, it can not be claimed that walking for 1 hours every day for 3 months would result in weight reduction.
Before conducting a paired sample t-test there are certain assumptions you must make about your data set.
In conclusion, a paired sample t-test is an effective statistical test used to compare the means of two samples. It should be used whenever you wish to determine if there is a statistically significant difference between two related or paired groups. The assumptions for this type of analysis must be met in order to get reliable and accurate results. This includes observations within the two samples being related or paired in a meaningful way, all observations being independent of each other, data normally distributed with similar variances and means, and equal sample sizes. With these assumptions in mind, a paired sample t-test can provide reliable and accurate results.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
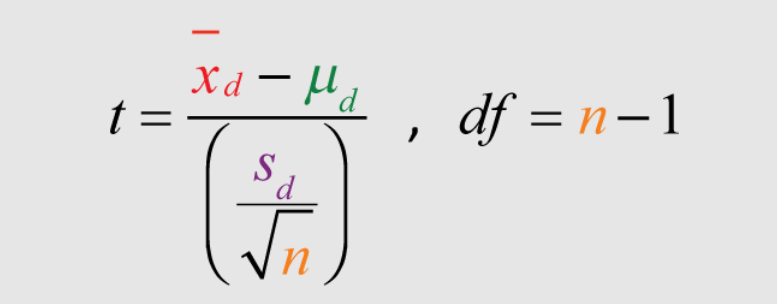{kind=link}
{kind=link}