Do you want to build cutting-edge NLP models? Have you heard of Huggingface Transformers? Huggingface Transformers is a popular open-source library for NLP, which provides pre-trained machine learning models and tools to build custom NLP models. These models are based on Transformers architecture, which has revolutionized the field of NLP by enabling state-of-the-art performance on a range of NLP tasks.
In this blog post, I will provide Python code examples for using Huggingface Transformers for various NLP tasks such as text classification (sentiment analysis), named entity recognition, question answering, text summarization, and text generation.
I used Google Colab for testing my code. Before getting started, get set up with transformers using the following code:
# Install Huggingface Transformers
#
pip install transformers
Text classification is a common NLP task that involves assigning predefined categories to text. It is widely used in various real-world applications, such as analyzing customer reviews, social media sentiment analysis, etc. For instance, in customer review analysis, businesses use text classification to categorize reviews into positive, negative, or neutral sentiments. This helps them understand their customers’ opinions and feedback, enabling them to improve their products or services.
The following code uses the Huggingface Transformers pipeline for text classification, which is designed to classify text into one or more categories. The pipeline is initialized with the “text-classification” task and then the code processes a given text to output its predicted class along with its confidence score. The input for each pipeline is a string or list of strings, and its output is a list of predictions. The predictions are in the form of a Python dictionary, which can be easily visualized as a Dataframe using Pandas. A sample text is provided as input to the pipeline for sentiment analysis.
from transformers import pipeline
import pandas as pd
#
# Pipeline initialized with the "text-classification"
#
classifier = pipeline("text-classification")
#
# Text classification
#
text = "British Godfather of AI, Geoffrey Hinton, QUITS Google over fears the 'scary' tech he pioneered 'may soon be more intelligent than us' - as scientist becomes latest expert to speak out against dangers of artificial intelligence."
outputs = classifier(text)
pd.DataFrame(outputs)
The above text sentiment is found to be NEGATIVE with a confidence score of 0.996605.
Named entity recognition is another common NLP task that has various real-world applications. For example, in the news industry, NER can be used to extract named entities such as people, locations, and organizations from news articles. This can help in automating tasks such as identifying key players in a news story, and extracting relevant information. In the medical industry, NER can be used to extract named entities such as drug names, dosage, and side effects from electronic health records. There are many other applications which can leverage NER.
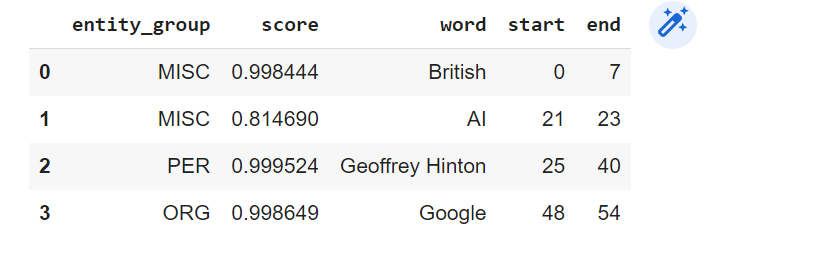
The code below uses the Huggingface Transformers pipeline for named entity recognition (NER). NER is an NLP task that involves identifying named entities (such as people, organizations, and locations) in a given text.
The pipeline is initialized with the “ner” task and the “simple” aggregation strategy. Other strategies available for usage include “first” and “average”. The code processes a given text to extract named entities from it. The named entities are returned as a list of dictionaries containing the entity text, its label, and the start and end position of the entity in the original text. To better visualize the output, the results are then converted into a Pandas dataframe.
from transformers import pipeline
import pandas as pd
#
# Pipeline initialized with the "ner" for named entity recognition
#
ner_processor = pipeline("ner", aggregation_strategy="simple")
#
# Extract named entity
#
text = "British Godfather of AI, Geoffrey Hinton, QUITS Google over fears the 'scary' tech he pioneered 'may soon be more intelligent than us' - as scientist becomes latest expert to speak out against dangers of artificial intelligence."
outputs = ner_processor(text)
pd.DataFrame(outputs)
The following is how the output would look like:
Question answering is a useful NLP task that has various real-world applications. For example, in customer support, question answering can be used to provide quick and accurate answers to frequently asked questions. In the education industry, question answering can be used to create intelligent tutoring systems that can help students learn and understand complex topics.
This code below uses the Huggingface Transformers pipeline for question answering. The question answering task involves answering a question based on a given context or passage of text.
The pipeline is initialized with the “question-answering” task. Then, the code provides a text and a question as input to the pipeline. The pipeline processes the input and returns a dictionary containing the answer to the question and its confidence score. To better visualize the output, the results are then converted into a Pandas dataframe.
from transformers import pipeline
import pandas as pd
#
# Pipeline initialized with "question-answering"
#
reader = pipeline("question-answering")
#
# Text from which questions will be asked
#
text = "British Godfather of AI, Geoffrey Hinton, QUITS Google over fears the 'scary' tech he pioneered 'may soon be more intelligent than us' - as scientist becomes latest expert to speak out against dangers of artificial intelligence."
#
# Question answering
#
question = "Who is godfather of AI?"
outputs = reader(question=question, context=text)
pd.DataFrame([outputs])
The following will be printed as a result of executing the above code:
Text summarization is yet another useful NLP task that has various real-world applications. For example, in the news industry, text summarization can be used to create short summaries of news articles, enabling readers to quickly understand the key points of a story. In the financial industry, text summarization can be used to summarize financial reports, enabling investors to quickly understand the key takeaways.
The following code uses the Huggingface Transformers pipeline for text summarization. The text summarization task involves generating a shorter version of a longer text while retaining its most important information.
The pipeline is initialized with the “summarization” task. The code provides a text as input to the pipeline along with parameters such as “max_length” and “clean_up_tokenization_spaces”. The code prints the summary text.
from transformers import pipeline
#
# Pipeline initialized with "summarization"
#
summarizer = pipeline("summarization")
text = "Machine learning impacts many exciting areas throughout our company. Historically, personalization has been the most well-known area, where machine learning powers our recommendation algorithms. We’re also using machine learning to help shape our catalog of movies and TV shows by learning characteristics that make content successful. We use it to optimize the production of original movies and TV shows in Netflix’s rapidly growing studio. Machine learning also enables us to optimize video and audio encoding, adaptive bitrate selection, and our in-house Content Delivery Network that accounts for more than a third of North American internet traffic. It also powers our advertising spend, channel mix, and advertising creative so that we can find new members who will enjoy Netflix."
outputs = summarizer(text, max_length=75, clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])
The following text gets printed as the summary:
Machine learning impacts many exciting areas throughout Netflix. Machine learning also enables us to optimize video and audio encoding, adaptive bitrate selection, and our in-house Content Delivery Network. It also powers our advertising spend, channel mix, and advertising creative so that we can find new members who will enjoy Netflix.
Text generation use case in the recent times have taken the world by storm, thanks to ChatGPT. For example, in the customer service industry, text generation can be used to generate personalized responses to customer complaints, enabling companies to provide quick and efficient customer service. In the journalism industry, text generation can be used to generate news articles or summaries, enabling journalists to quickly produce content for their readers. In the creative writing industry, text generation can be used to generate new stories or poems, enabling writers to quickly generate new ideas and explore different writing styles. In the code samples below, text generation use case is demonstrated to deal with customer complaints.
The following code uses the Huggingface Transformers pipeline for text generation. The text generation task involves generating new text based on a given prompt or context. The code first provides a prompt text as input, which is a customer complaint about a faulty product. Then, the pipeline is initialized with the “text-generation” task. The pipeline processes the input and generates a new response text from the customer service representative’s perspective. In the code, we print the generated text.
from transformers import pipeline
text = "Dear Sir, I am writing to express my disappointment with the product that I recently purchased from your website. I ordered a pair of wireless headphones on April 20th, 2023, which was supposed to arrive on April 25th, 2023. However, the product didn't arrive until May 2nd, 2023, which caused a significant inconvenience for me.When I finally received the package, I was disappointed to find that the headphones were not functioning correctly. The left earbud produces distorted sound, and the right earbud doesn't work at all. I have tried everything I could to fix the problem, including resetting the headphones and trying them with different devices, but the issue persists. I am incredibly frustrated with this purchase and would like to return the product and receive a full refund. I expect a prompt response and a resolution to this matter as soon as possible. I have been a loyal customer of Amazon for many years, and I hope that this issue can be resolved quickly to maintain my trust in your brand."
generator = pipeline("text-generation")
response = "Dear customer, I am sorry to hear that your headphones are not functioning properly."
prompt = text + "\n\nCustomer service response:\n" + response
outputs = generator(prompt, max_length=500)
print(outputs[0]['generated_text'])
In this blog post, we explored various NLP tasks and their implementation using Huggingface Transformers. We’ve shown how to use pre-trained models and pipelines to perform text classification, named entity recognition, question answering, text summarization, and text generation. By leveraging the power of Huggingface Transformers, we can build robust and accurate NLP models that can help automate and streamline various real-world applications. We hope this blog post has given you a better understanding of how to use Huggingface Transformers for your own NLP projects and inspired you to explore further.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}