In recent years, there has been an explosion of interest in machine learning (ML). This is due in large part to the availability of powerful and affordable hardware, as well as the development of new ML algorithms that are able to achieve state-of-the-art results on a variety of tasks. However, one of the challenges of using ML is that many algorithms require a large amount of data and computational resources in order to train a model that generalizes well to new data.
To address this challenge, a number of model compression techniques have been developed that allow for the training of smaller, more efficient models that still achieve good performance on a variety of tasks. In this blog post, we will review some of the most popular model compression techniques and discuss their benefits and drawbacks.
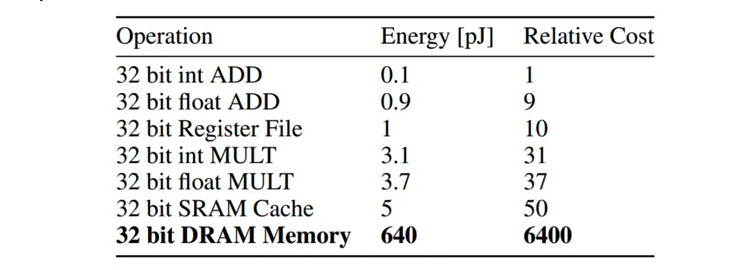
Deep neural networks (DNN) or deep learning models are generally optimized for high performance in terms of prediction accuracy. As a result, deep learning models are very large and have huge number of parameters (million parameters or more). These models become of huge size and takes large space on the storage devices. For example, AlexNet has around 61 million parameters and takes around 200MB of space. These DNN models can be trained using high-end GPUs. However, using such processors for predictions can be highly limiting owing to the limited storage and computing power of the devices. For example, mobile devices which needs faster predictions would ideally need to store models on the device and do predictions. And, accessing models from SRAM rather than DRAM could be ideal as that would need very less energy and hence battery power.
Observe how accessing the data from 32 bit SRAM cache takes much less energy and cost much less than accessing the data from DRAM memory. Based on above data, one could infer that it would be ideal for the DNN models to be compact enough to fit on SRAM for lesser energy / battery consumption. This is where different model compression techniques could help a great deal.
Pruning is a technique for reducing the size of a model, with the goal of improving efficiency or performance. Pruning can be applied to both deep neural networks and shallow machine learning models. In general, pruning works by removing unnecessary or redundant parameters or connections which are not sensitive to model performance. This can be done either manually or automatically, depending on the pruning algorithm being used.
There are a number of different pruning techniques that can be used for model compression in machine learning. The following are some of them:
Low-rank factorization is a technique for model compression that has gained popularity in recent years. It is a technique that involves approximating a matrix with a lower-rank matrix in order to store them more efficiently while preserving as much information as possible. This can be done by using singular value decomposition (SVD) or by using other methods such as eigenvalue decomposition. This technique can be used to compress any type of matrix, including those representing neural networks. Low-rank factorization has been shown to be effective at reducing the size of neural networks without compromising performance. In addition, the factored matrices can be stored in a way that is more efficient than the original matrix. As a result, this technique can be used to reduce the memory requirements of machine learning models.
Low-rank factorization can be used to compress both deep neural networks (DNNs) and shallow neural networks (SNNs).
Quantization is a technique for model compression that is often used in machine learning. By reducing the number of bits needed to represent data, quantization can significantly reduce storage and computational requirements. In addition, Quantization can also improve the performance of neural networks by reducing the amount of noise in the data. There are a variety of ways to perform quantization, but one common approach is to first train a model with high precision, then compress the model by replacing weights with lower-precision equivalents. This can be done using a variety of methods, such as Huffman coding or entropy coding. Quantization can also be performed on the activations of a neural network, rather than the weights. This is often called “post-training quantization” and can provide even greater compression ratios. Quantization can be used to compress both DNNs and SNNs.
Knowledge distillation is a technique for model compression that can be used to improve the performance of machine learning models. It involves training a small model to imitate the behavior of a larger model. This can be done by providing the smaller model with labels generated by the larger model, or by providing the smaller model with the output of the larger model’s intermediate layers. Knowledge distillation can be used to improve the performance of many different types of models, including deep neural networks. When used properly, it can help to reduce the size of models without sacrificing accuracy. Knowledge distillation can be used to compress both DNNs and SNNs.
Transferred Convolutional Filters is a technique that can be used for model compression in machine learning. Transferred Convolutional Filters can be used to compress the size of a model by designing specific structural convolutional filters which can result in saving the parameters.
There are a number of different model compression techniques that can be used to reduce the size of machine learning models without sacrificing too much performance. In this blog post, we reviewed some of the most popular model compression techniques, including pruning, low-rank factorization, quantization, and knowledge distillation. Each technique has its own benefits and drawbacks, so it is important to choose the right technique for the task at hand.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}