sonar code maintainability
This article talks about 4 different quality parameters found on Sonar dashboard which could help measuring code maintainability. Following are those quality parameters:
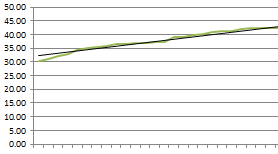
Greater test coverage depicts that developers are focusing on writing good unit tests for their code which results in greater test coverage. This also depicts the fact that the code is testable and hence, easier to change as a bad change could lead the unit tests to fail and raise the red flag. And, a code easier to change becomes a code easier to maintain. One another important thing to note is the fact that the focus should be given to capture the trending of test coverage over multiple releases to see if the test coverage is increasing or decreasing. For this purpose, one could use the “time machine” of the sonar. Following is a sample test coverage trendline which depicts the test coverage across severel releases.
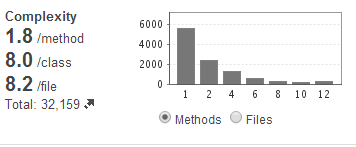
Code complexity, in above diagram, depicts the conditional expressions present in the method and classes. A higher code complexity depicts that there are multiple conditional expressions in the class. This impacts the testability of the code (and hence code maintainability) as it becomes very difficult to write the unit tests having great coverage of such methods or classes. Additionally, it also impacts the read-ability and understandability of the code and hence code usability. Again, as mentioned in above point, it would be interesting to capture the trending of code complexity over multiple releases to check if the code complexity is increasing or decreasing.
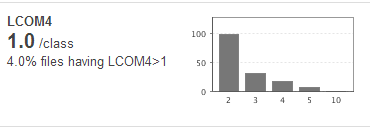
In above diagram, you would see that 4% of files have LCOM index greater than 1. This indicates the fact that 4% of files have code which is serving more than one responsibility and thus, could be difficult to change. In another words, 4% of files are less cohesive in nature and hence have lesser re-usability. From object oriented principles perspective, 4% of files violates the single responsibility principle. And, the files which violates the SRP could be seen as files that are difficult to change and hence, difficult to maintain.
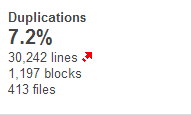
This is fairly simple to infer. Greater code duplication indicates that code is very difficult to maintain as one needs to update in multiple places if the functionality related with duplicated block of code changes.
[adsenseyu1]
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Hi,
I like the way you summarized these metrics.
I would also add the cyclomatic dependencies as a good to check metric.
More than once I found out that we grouped packages the wrong way.
Regarding the complexity, I get annoyed by the fact that it counts the 'equals' method, which, if you generate it using eclipse, you get high complexity.
I haven't deeply looked how to remove only 'equals' (and hashcode for that matter) in Sonar.
Woh I your posts, saved to fav!