Following are the key points described later in this article:
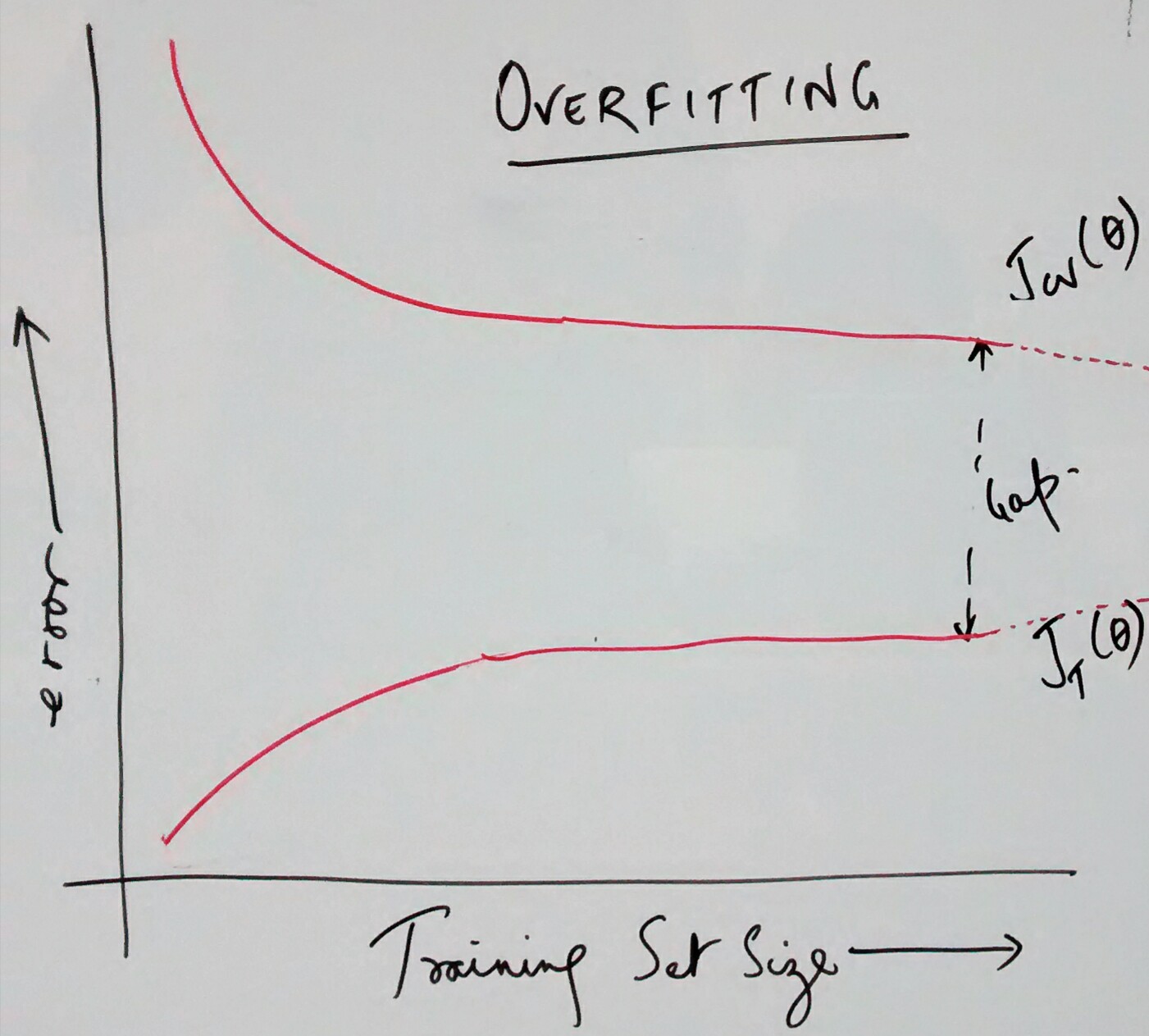
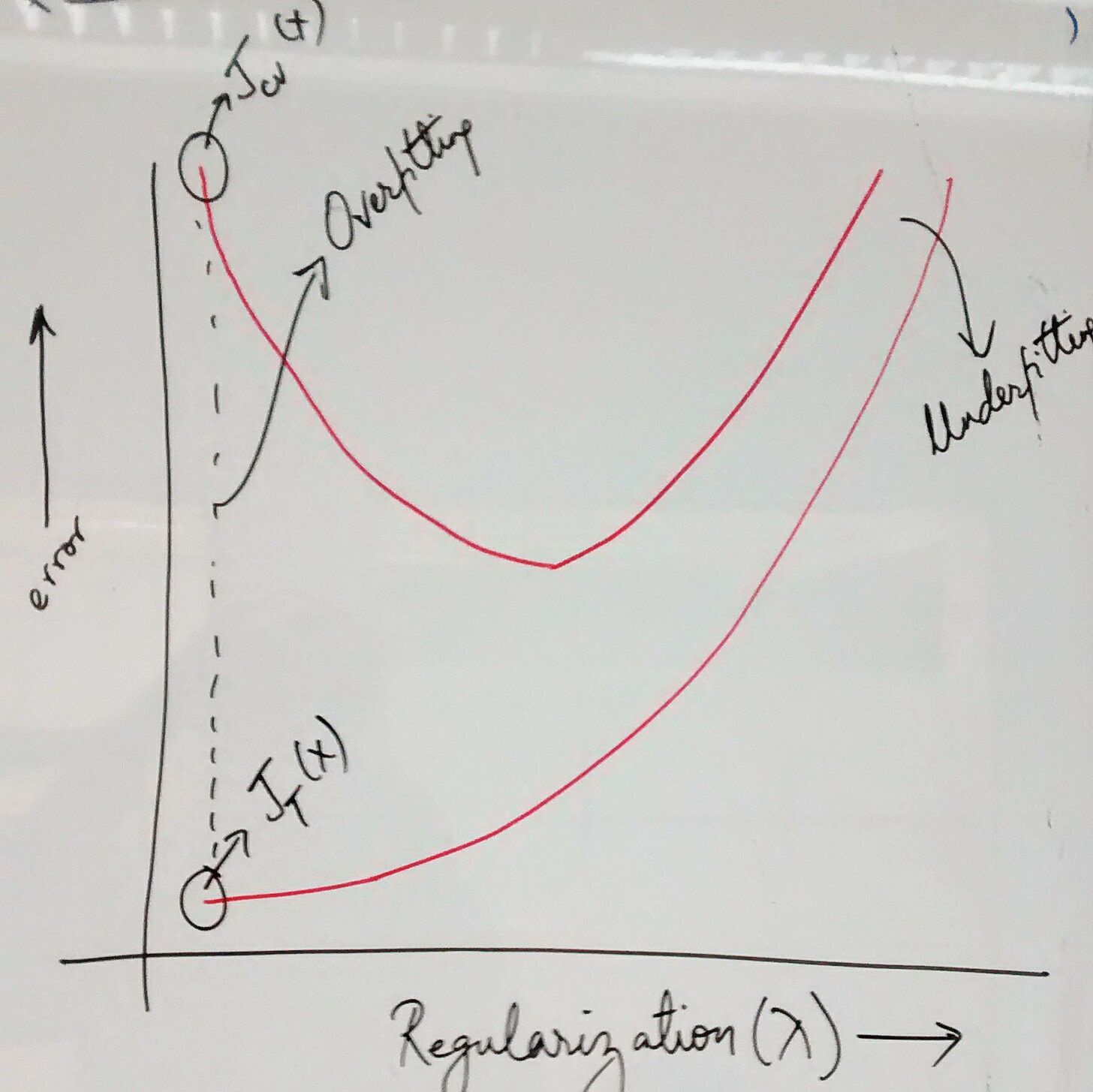
When working with machine learning algorithm, the primary objective is to minimize the error between predicted and observed value by minimizing the cost function which, for regression models, is mean squared difference between predicted and observed value (added with regularization if required). Below argument can as well be applied for neural network. Following are different reasons why large prediction errors could be found while working with linear or logistic regression models.
Following are some of the techniques that one could use to reduce the prediction error and further optimize the regression models. Note that the error results from common reasons such as high bias (under-fitting) or high variance (over-fitting)
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}