When working with Python-based machine learning models, a common question that pops up is how do we invoke models written in Python from apps written in other languages?
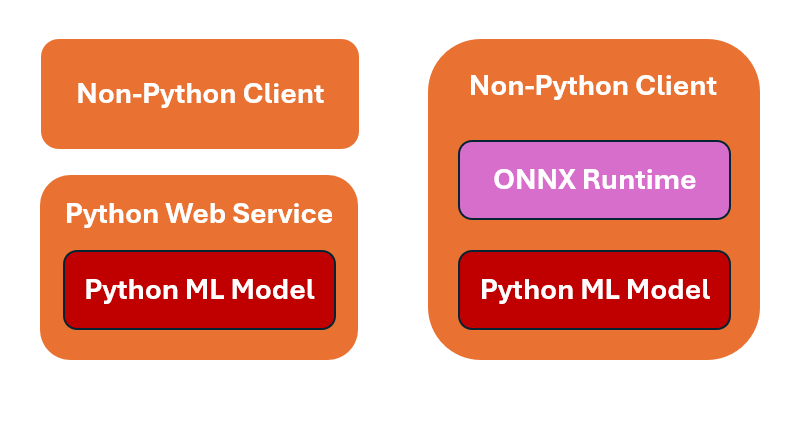
The picture below represents two strategies for invoking Python machine learning models from client applications written using other programming languages such as Java, C++, C#, etc.
The following is explanation for the above:
The following is the sample Python Flask application to work with a pre-trained ML model saved as model.pkl (pickle file). Non-python client can invoke this webservice appropriately. The model is loaded once when the server starts, ensuring efficient use of resources. The /predict endpoint accepts POST requests containing JSON data. It extracts the necessary features, makes a prediction using the loaded model, and returns the result in JSON format.
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
# Load the pre-trained model
with open('model.pkl', 'rb') as f:
model = pickle.load(f)
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
# Assuming the input data is a dictionary of features
features = [data['feature1'], data['feature2'], data['feature3']]
prediction = model.predict([features])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)
The above code can be tested using curl or Postman. Here is the sample curl code:
curl -X POST http://localhost:5000/predict \
-H "Content-Type: application/json" \
-d '{"feature1": 5.1, "feature2": 3.5, "feature3": 1.4}'
The process of exporting a Python model to ONNX varies depending on the framework used to build the model. In the code sample below, we will be exporting model from Scikit-learn.
First and foremost, we need to install ONNX runtime. Here is the code.
pip install scikit-learn skl2onnx onnxruntime
Let’s say we have trained a logistic regression model and we created a pickle file namely, logistic_model.pkl. In the code below, The trained Scikit-learn model is loaded using joblib. The convert_sklearn method is used to convert the Scikit-learn model to ONNX format.
# export_sklearn_to_onnx.py
import joblib
from sklearn_model import model
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Load the trained Scikit-learn model
model = joblib.load("logistic_model.pkl")
# Define the initial type
initial_type = [('float_input', FloatTensorType([None, 4]))] # Iris dataset has 4 features
# Convert the model to ONNX
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the ONNX model
with open("logistic_model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
print("Scikit-learn model has been converted to ONNX format and saved as 'logistic_model.onnx'")
The converted model is serialized and saved as an onnx file. Once the model is exported to ONNX format, we can use ONNX Runtime to load and perform inference. The following steps are performed for inference:
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}