Supervised and unsupervised learning are two different common types of machine learning tasks that are used to solve many different types of business problems. Supervised learning uses training data with labels to create supervised models, which can be used to predict outcomes for future datasets. Unsupervised learning is a type of machine learning task where the training data is not labeled or categorized in any way. For beginner data scientists, it is very important to get a good understanding of the difference between supervised and unsupervised learning. In this post, we will discuss how supervised and unsupervised algorithms work and what is difference between them.
You may want to check my post on what is machine learning to get a detailed view of different concepts.
Supervised vs Unsupervised Learning Tasks
The following represents the basic differences between supervised and unsupervised learning are following:
- In supervised learning tasks, machine learning models are created using labeled training data. Whereas in unsupervised machine learning task there is no labels or category associated with training data.
- Supervised learning models help predict outcomes for future data sets, whereas unsupervised learning allows you to discover hidden patterns within a dataset without the need for human input.
Let’s try and understand the details of supervised and unsupervised learning with the help of examples.
What is Supervised learning?
Supervised learning is a type of machine learning where the training data must include labels. For example, if we were training a supervised learning algorithm to classify handwritten digits, the training data would include images of handwritten digits along with the corresponding labels (i.e., the correct digit for each image). Supervised learning algorithms learn from the training data and build a model that can be used to make predictions on new data. The supervised machine learning task can be used to predict outcomes for future datasets that are similar to the labeled datasets. Supervised models use labels, which act as a guide to help create an accurate model. The below represents examples of supervised learning problems:
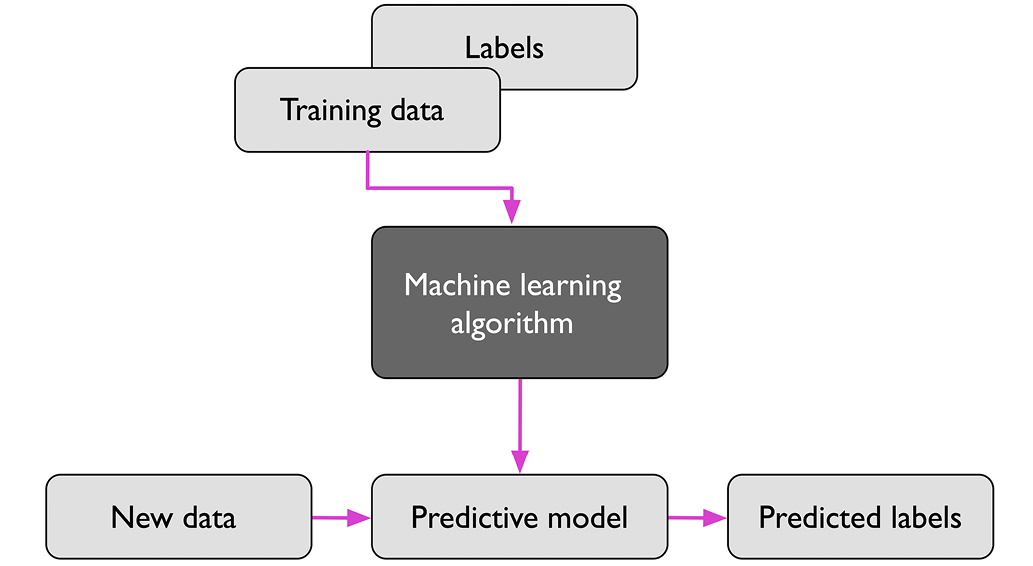
The following picture represents machine learning models building using supervised learning process. The picture is taken from the book, Machine Learning with PyTorch and Scikit-Learn.
There are mainly two main types of supervised learning algorithms such as classification algorithms and regression algorithms.
- Classification algorithms are used when the target variable is categorical (e.g.,digit). Let’s understand with an example. For example, in a classification task with two classes (e.g. “positive” and “negative”), the training set would be a collection of data points, where each data point is labeled as either “positive” or “negative”. The supervised learning algorithm would then learn to classify new data points as either “positive” or “negative” based on the training set.
- Regression algorithms are used when the target variable is numerical (e.g., prices). In case of linear regression models, we are given a set of training data, and we want to find the line that best describes this data. To do this, we minimize the sum of the squared distances between each point and the line. This gives us the equation for the line, which we can then use to make predictions on new data points. Let’s understand with an example. Supervised learning can be used to predict the price of a house based on historical data. In this case, the dataset would be labeled with the sale price of the house and other features such as square footage, number of bedrooms, etc. The supervised learning algorithm would then learn from this labeled dataset and be able to predict the sale price of a new house based on the same features.
Note some of the following in the above diagram representing supervised learning problem:
- Input represents the training data without a label
- The output represents the label found in the training data. Note that the label column represents the response or dependent variable. The variable that needs to be predicted.
- The application represents details on real-world applications.
Here is the detail of some of the supervised learning problems listed in the above diagram:
- Housing price prediction: One supervised learning example is housing price prediction, in which a model is trained on historical data of housing prices and features in order to predict the future sale price of a given house. This is a regression task, as the output (housing price) is continuous. supervised learning algorithms that could be used for this task include linear regression, decision trees, and random forests. The inputs (features) could include the size of the house, the number of bedrooms and bathrooms, the location, and other amenities. The model would be trained on a dataset of past housing sales, and then given a new set of input features to predict the selling price. This type of model could be used by real estate agents to help price homes for sale, or by homebuyers to get an estimate of what a particular house may be worth.
- Whether the user will click on an ad: Supervised learning can be used to predict whether a user will click on an ad or not. This supervised machine learning task uses historical data of prior users’ actions and attributes from the advertisement campaign as input variables, which are then classified into two classes: “click (1)” and “not click (0)”
- Image classification: Supervised learning can be used to classify images into one of the many different categories. In the above diagram, 1000 categories are shown. This supervised machine learning task uses training data with labeled images in order to create supervised models that can predict which category an image belongs in based on its features.
What is Unsupervised learning?
Unsupervised learning is a type of machine learning that focuses on giving a computer the ability to learn from data without being given any prior labels or categories. This is in contrast to supervised learning, which involves providing a computer with training data that has been previously labeled. Some common unsupervised learning algorithms include k-means clustering and Principal Component Analysis (PCA). Unsupervised learning can be used for a variety of tasks, such as dimensionality Reduction, market segmentation, and novelty detection. The unsupervised machine learning task is often used to discover hidden patterns or correlations within a dataset, which can be very useful for business owners who want to understand their customers better and make more informed decisions based on this information. The following represents some of the examples of unsupervised learning problems:
- Customer segmentation: Unsupervised learning is often used to segment customers and groups of similar behavior together. By using this unsupervised machine learning task, companies can create segments within their customer base that represent different types of consumers with distinct needs or criteria based on common characteristics such as demographics or interests.
- Market basket analysis: Market basket analysis uses association rules to discover hidden product relationships that are often not apparent to the customer. This unsupervised machine learning task can be used by businesses to understand their customers’ shopping habits and identify which products are commonly purchased together in order to optimize pricing or product placement on shelves.
- Document categorization: Unsupervised learning is often used to automatically categorize documents into different topics or categories. This unsupervised machine learning task allows businesses to understand the types of content that their customers are sharing, which can help them establish a social media presence and gather more information from online sources.
- Marketing campaign optimization: Unsupervised learning can be used to optimize campaigns by grouping customers into different categories based on their interests or purchase history. This unsupervised machine learning task is often performed with segmentation in mind, which helps companies understand how best to speak to each of their customer groups and deliver the right message at the right time.
The following is a self-explanatory picture representing what is supervised and unsupervised learning techniques and how are they different.
Figure 1. Supervised vs Unsupervised Machine Learning Problems
Pay attention to some of the following:
- Supervised learning: In supervised learning problems, predictive models are created based on an input set of records with output data (numbers or labels). Based on the outcome/response or dependent variable, supervised learning problems can be further divided into two different kinds:
- Regression: When the outcome or response variable is a continuous variable (numeric or number), it can be called a regression problem.
- Classification: When the outcome or response variable is a discrete variable (labels), it can be called classification problems.
- Unsupervised learning: In unsupervised learning, patterns or structures are found in data and labeled appropriately.
Supervised and Unsupervised Learning Algorithms
The following diagram represents information in relation to algorithms that can be used in the case of supervised and unsupervised machine learning.
Figure 2. Supervised vs Unsupervised Machine Learning Algorithms
Pay attention to some of the following:
- Supervised learning algorithms
- Regression: Linear regression, Support vector regression (SVR), ensemble methods, polynomial regression, Lasso/ridge regression, neural networks
- Classification: Logistic regression, decision trees, random forest cllassifier, support vector machine classifier (SVM), linear discriminant analysis, Naive Bayes, K-Nearest Neighbours (KNN)
- Unsupervised learning algorithms
- Clustering algorithms:
- K-means: K-means is a type of unsupervised learning that is used to cluster data into groups of similar points. It is one of the simplest and most commonly used clustering algorithms. K-means works by calculating the distance between data points and grouping them together based on their similarities. The algorithm starts by randomly selecting K data points, which are then used as the centroids for each group. Data points are then assigned to the group whose centroid is closest to them. The centroids are then updated to the mean of all the data points in their group. This process is repeated until the centroids converge or a predetermined number of iterations has been reached. K-means is typically used for tasks such as customer segmentation, image compression, and pattern recognition.
- K-medoids: K-medoids is a variation of the K-means algorithm, which is a popular clustering method. Instead of using the mean of each cluster as the centroid, K-medoids uses one of the data points in the cluster as the medoid. This medoid is then used to represent the entire cluster. K-medoids is more robust than K-means because it is less sensitive to outliers. It can also handle non-numeric data better than K-means. K-medoids is typically used for small or medium-sized datasets.
- Hierarchical clustering: Hierarchical clustering is a type of unsupervised learning that is used to group data points into clusters. This method is often used when there is no clear dividing line between different groups of data. Hierarchical clustering starts by assigning each data point to its own cluster. Then, the algorithm looks for pairs of clusters that are similar and merges them together. This process continues until all the data points are grouped into a single cluster. Hierarchical clustering can be used with any type of data, but it is particularly useful for large data sets where other methods may be too computationally intensive.
- Gaussian mixture models: Gaussian mixture models (GMM) is a clustering algorithm that models each cluster as a mixture of multiple Gaussian distributions. It is an unsupervised learning algorithm that can be used for density estimation, clustering, and data compression. GMM can be used to solve problems such as identifying different subgroups of customers based on their purchasing behavior. One of the main advantages of GMM is its flexibility in modeling data with complex patterns. It can model data with non-linear boundaries and can capture the covariance structure of the data. Additionally, GMM allows for probabilistic clustering, meaning that each data point can belong to multiple clusters with different probabilities.
- DBSCAN
- Spectral clustering
Summary
In this post, you learned (visually) about what is supervised and unsupervised learning and how are they different. Supervised and unsupervised machine learning are two different types of tasks that can be used to extract useful information from labeled and unlabeled data respectively. Supervised learning happens when there are labels associated with the training dataset, whereas in unsupervised learning, there are no labels or categories given to the training data. Supervised learning often helps predict outcomes for future datasets while unsupervised allows you to find hidden patterns within a dataset without human intervention. Both supervised and unsupervised machine learning tasks have many different uses depending on what your business needs may be.
Latest posts by Ajitesh Kumar
(see all) 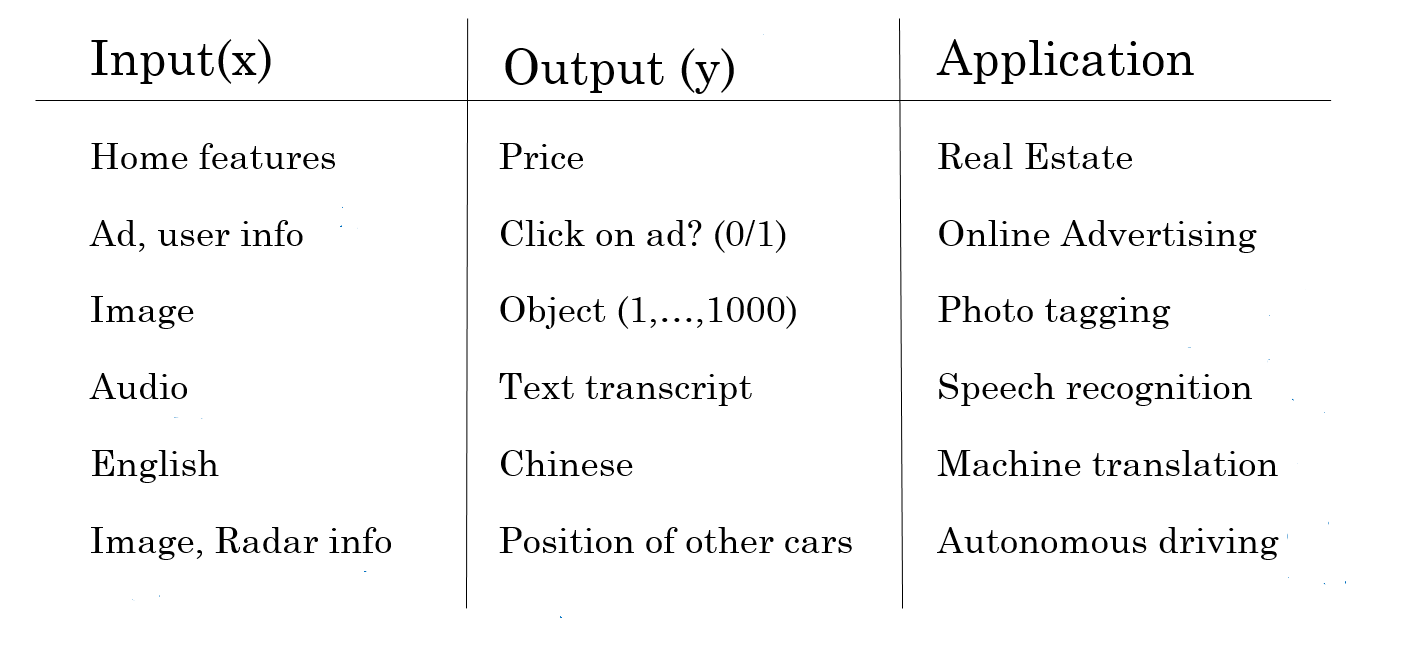{kind=link}
{kind=link}