In machine learning, confounder features or variables can significantly affect the accuracy and validity of your model. A confounder feature is a variable that influences both the predictor and the outcome or response variables, creating a false impression of causality or correlation. This makes it harder to determine whether the observed relationship between two variables is genuine or merely due to some external factor.
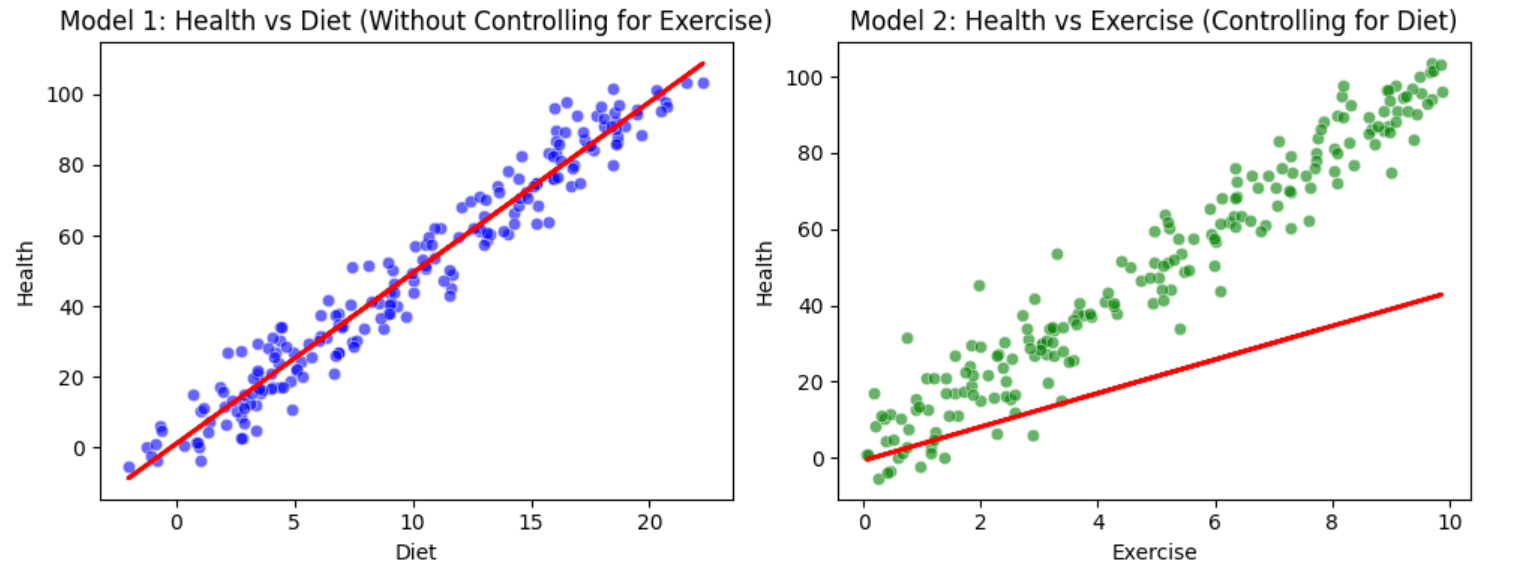
For instance, consider a model that predicts a person’s likelihood of heart disease based on their diet. You may conclude that people eating a balanced diet are less likely to have heart disease, but this relationship could be confounded by exercise habits. People who eat well are also more likely to exercise, and exercise itself is an important factor influencing heart health. If exercise is not properly accounted for in the model, the impact of diet might be overestimated. This is a classic example of a confounding feature: exercise influences both the diet and the outcome (heart health), leading to a potential bias in your conclusions. The following plot represents the impact of including confounder features while training machine learning models:
Make a note of the following in above pictures:
Let’s look at another example. In a predictive model for housing prices, both the proximity to good schools and neighborhood affluence might influence the price. If you’re interested in the effect of school proximity on housing prices, affluence is a confounder that needs to be accounted for, as it is related to both variables.
Incorporating the concept of confounder features into your ML model building is beneficial for several reasons:
Identifying whether features are confounding in nature can be done through various methods:
Correlation Analysis: This is one of the most common approaches. It involves measuring the statistical relationships between different features and the target variable to identify indirect influences.
Causal Diagrams: Another effective approach is the use of causal diagrams or Directed Acyclic Graphs (DAGs), which help visualize relationships between different variables and identify possible confounding paths.
Machine learning models often need to separate the predictor feature from the confounders to ensure accurate results. By understanding and addressing the confounders, data scientists and researchers can make more precise and unbiased models, enabling better decision-making and insights in complex environments.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}