As technology advances, new data streaming solutions emerge to meet the ever-growing demand for real-time analytics. Two popular options are Amazon Kinesis and Apache Kafka. Here, we’ll take a look at these two platforms and compare them in terms of their core concepts and differences.
Amazon Kinesis is an AWS serverless streaming service that allows you to collect, process, and analyze streaming data in real time. It is a fully managed service that can capture, store, and analyze hundreds of terabytes of data from millions of sources simultaneously. It is designed to be highly available and scalable so that your streaming data can be reliably processed without any downtime or disruption. And, the best part is the capacity for Kinesis can scale “on-demand”. This essentially means that one does not need to provision and scale resources up or down manually before data volume increases or decreases.
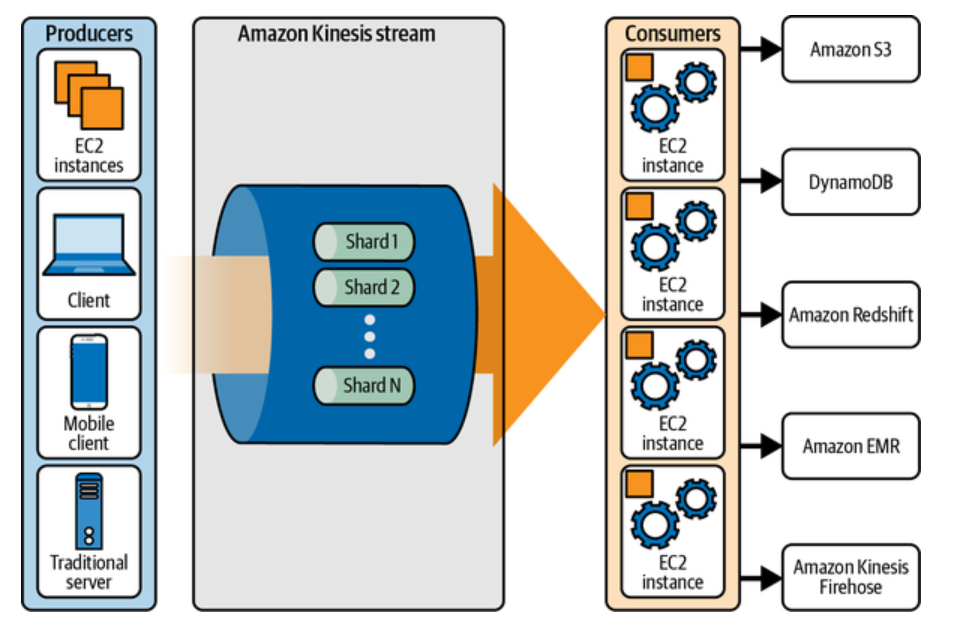
The picture below represents Amazon Kinesis and how it helps managing data streams with upstream data sources and downstream applications.
Kinesis offers four main components – Kinesis Video Streams (KVS), Kinesis Data Streams (KDS), Kinesis Data Firehose (KDF), and Kinesis Data Analytics (KDA). The first three components allow you to collect streaming data from multiple sources and process it into readable formats. The fourth component enables you to perform analytics on the data streams for predictive insights.
The following are some of the advantages of working with Amazon Kinesis:
Apache Kafka is an open-source distributed streaming platform developed by the Apache Software Foundation. Apache Kafka provides client libraries that support streaming data to and from Kafka clusters. The service is bundled with the streaming analytics, data streaming and integration layer. Kafka streams are battle tested for low latency as low as 2 milliseconds subjected to network-limited throughput.
Apache Kafka provides a unified platform for handling real-time data feeds from multiple sources such as web servers, databases, message queues, etc., as well as for managing events in real time within applications. Kafka streaming service supports both batch processing and stream processing which makes it more flexible than other services. The following are some of the advantages / benefits of using Kafka service:
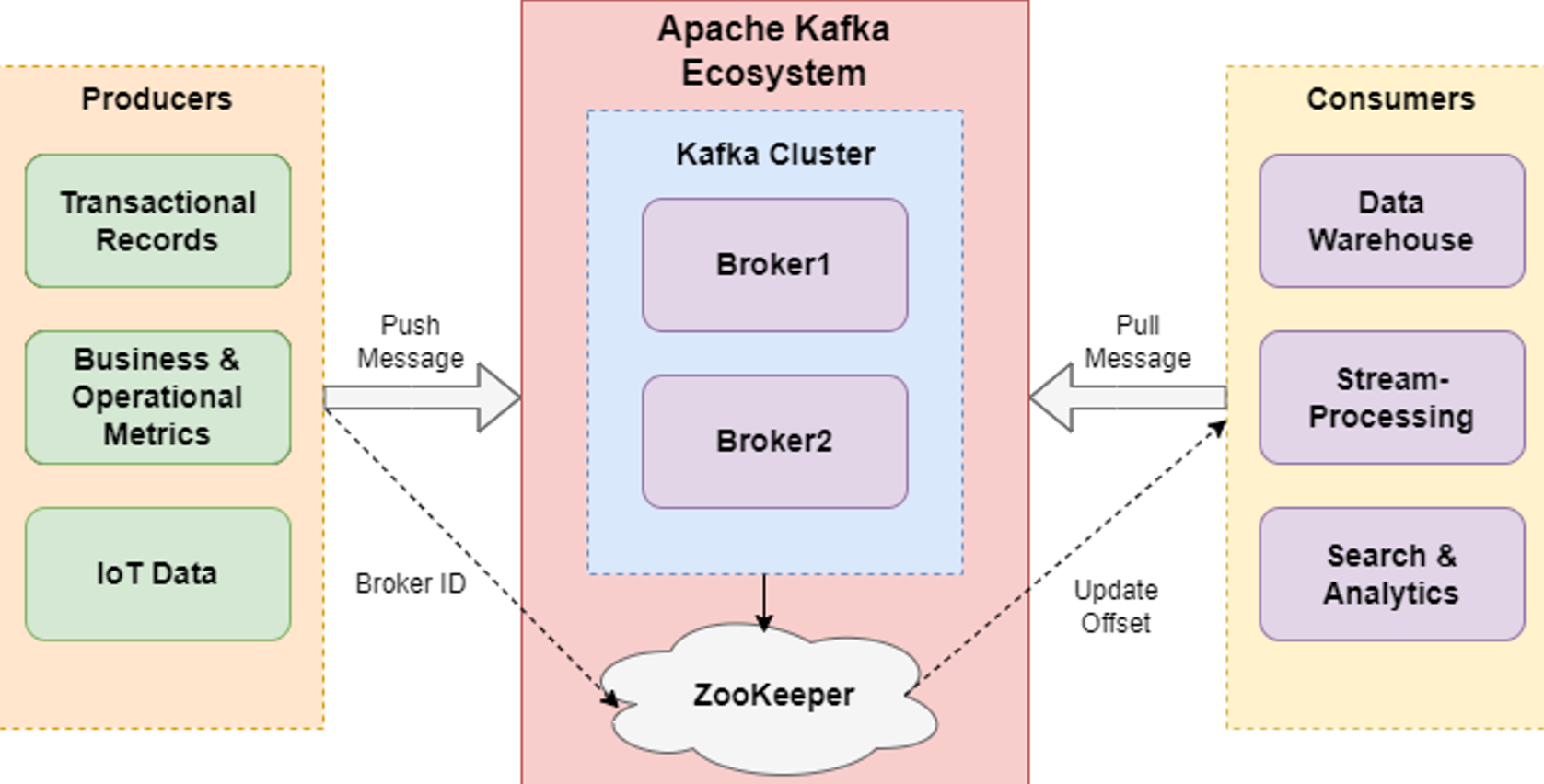
The picture below represents how Kafka is used in the real-world scenarios.
One example of Apache Kafka in use is Uber’s ride-sharing service. In order for Uber to accurately match riders with drivers, the company uses Apache Kafka as a messaging system to track and store data from riders who request rides. The system intakes various pieces of information, including the rider’s location, the driver’s location, and any other relevant information needed to make a match. By leveraging Kafka’s ability to ingest large amounts of data quickly, this process is much faster than it would be if handled manually.
Another example comes from Comcast. To provide better customer service experiences for their customers, Comcast leverages Apache Kafka technology as part of its customer experience platform. This platform allows Comcast to collect customer data in real-time and aggregate it into meaningful reports so they can improve their services accordingly. Additionally, the platform helps streamline operations like automated billing and smart device management so customers have an easier time managing their accounts and services.
The healthcare industry has also adopted Apache Kafka technology in order to monitor patient health more effectively. For instance, the Mayo Clinic uses Kafka’s technology to better detect abnormal patient behaviors in order to prevent potential medical emergencies or adverse events such as falls or heart attacks before they occur. The usage of this technology has allowed Mayo Clinic physicians to respond quicker and more efficiently if an adverse event does occur because they have access to complete real-time patient records that are updated in near real time through Kafka’s streaming analytics capabilities.
One of the key differences between Amazon Kinesis and Apache Kafka is the way in which they handle data. With Apache Kafka, data is stored on disk as a log file and then streamed to consumers. In contrast, Amazon Kinesis stores incoming data in shards before streaming it out to consumers. This means that shards are used to store records, while Apache Kafka stores messages only.
The most obvious difference between Amazon Kinesis and Apache Kafka is that the former is a fully managed service while the latter is an open-source platform with no official support or maintenance provided by any organization or company. This means that users must manage their own clusters when using Kafka while they do not have to worry about any operational tasks when using Kinesis since it is completely managed by AWS.
Amazon Kinesis can scale automatically according to usage needs, while Apache Kafka requires manual scaling. For example if you have an application deployed on Amazon Kinesis, it can automatically readjust its resources according to changes in user needs or incoming data. With Apache Kafka however, users must monitor their applications and manually adjust the number of nodes in order for them to remain operational.
Apache Kafka has been fund to have a higher learning curve in comparison to other streaming solutions like Kinesis.
Apache Kafka provides greater configurability including manually specifying the data retention period in comparison to Amazon Kinesis which keeps this fixed at 7 days.
When it comes to security both platforms offer reliable security measures but there are still some differences between them. Apache Kafka allows for greater control over access permissions since administrators can control who has access to certain data streams through role-based access control (RBAC). On the other hand Amazon Kinesis relies more heavily on AWS Identity & Access Management (IAM) policies as well as encryption at rest/in transit mechanisms.
Given the ease of setup for a managed solution like AWS Kinesis and integration with AWS stack of services, smaller data teams who are looking for quick time-to-value could go for adopting Amazon Kinesis. For more specific requirements, open source Apache Kafka can be used.
In terms of scalability and availability, both Amazon Kinesis and Apache Kafka offer high throughput levels but Apache Kafka is more reliable as it replicates its messages across multiple nodes by default. On the other hand, Amazon Kinesis does not provide this level of replication by default however users can configure the service to replicate messages across multiple servers for added reliability if needed.
Another difference between Amazon Kinesis and Apache Kafka is the cost associated with each service. With Apache Kafka users need to pay for infrastructure costs associated with running a cluster whereas Amazon Kinesis charges based on usage which makes it a more cost effective solution for smaller scale projects or those which consume small amounts of data. Additionally, Amazon Kinesis provides additional features such as CloudWatch integration which provides insight into usage and performance that isn’t available in Apache Kafka making it better suited for larger scale projects that require more sophisticated monitoring capabilities.
In conclusion, both Amazon Kinesis and Apache Kafka are powerful tools for collecting and processing streaming data in real time but they each have their own unique features that make them better suited for different types of use cases depending on your needs whether they be low latency requirements or batch processing capabilities etc. Ultimately though it comes down to personal preference as there are pros and cons associated with each one so make sure you do your research before making a decision!
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}