Machine learning models are often trained with a variety of different methods in order to create a more accurate prediction. Ensemble methods are one way to do this, and involve combining the predictions of several different models in order to get a more accurate result. When different models make predictions together, it can help create a more accurate result. Data scientists should care about this because it can help them create models that are more accurate.
In this article, we will look at some of the common ensemble methods used in machine learning. Data scientists should care about this because it can help them create models that are more accurate. According to a study, the use of ensemble methods can improve the accuracy of a machine learning model by up to 10%.
The five methods covered in the article are the following:
While bagging, boosting, and stacking are all types of ensemble methods. Voting is a type of ensemble method that involves combining the predictions of several different models and then choosing the prediction that has the most votes. Averaging is a type of ensemble method that involves combining the predictions of several different models and then taking the average of their predictions.
Bagging is a type of ensemble method that involves combining the predictions of several different models in order to create a more accurate result. When different models make predictions together, it can help create a more accurate result. Data scientists should care about this because it can help them create models that are more accurate.
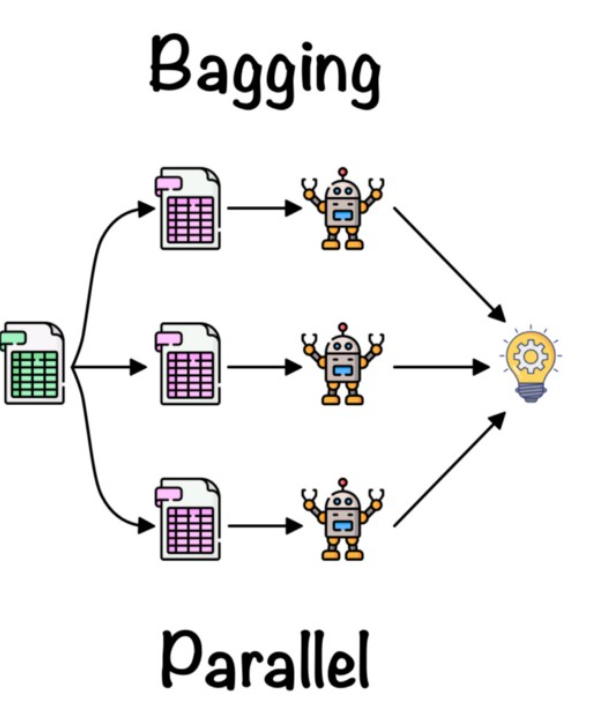
Bagging technique works by creating a number of models, called “bags”, each of which is based on a different randomly-selected sample of the data. This means that individual data points can be selected more than once. The predictions made by each bag are then averaged to produce a more accurate prediction. This helps to reduce the variance of the predictions and creates a more accurate prediction. According to a study, the use of ensemble methods can improve the accuracy of a machine learning model by up to 10%. Bagging is also known as bootstrap aggregation. The diagram below represents bagging ensemble method.
An example of application of the bagging method would be to create a model that predicts whether or not a customer will churn. This could be done by training several different models using different data sets and then averaging their predictions together. This would help to reduce the variance of the predictions and create a more accurate prediction.
Boosting is a type of ensemble method that helps to improve the accuracy of a machine learning model. It does this by combining the predictions of several different models and then adjusting the weights of the models so that the better models have more influence on the final prediction. This helps to improve the accuracy of the prediction.
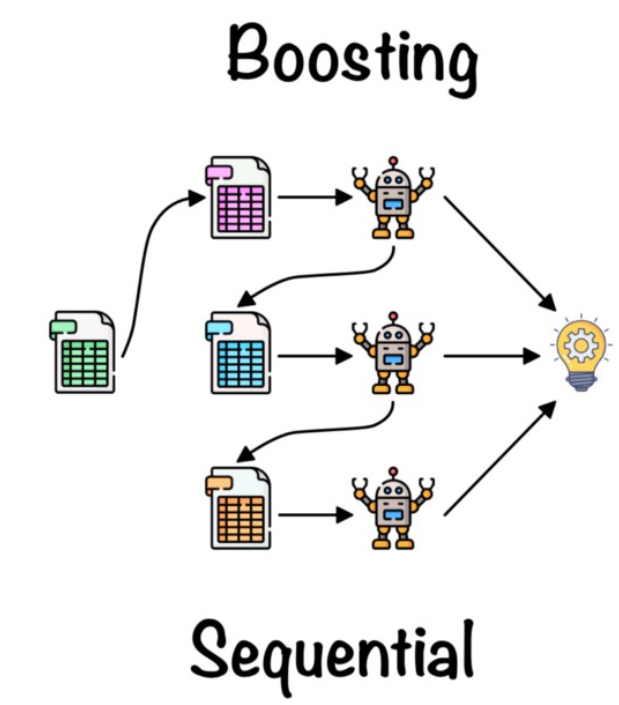
In boosting ensemble technique, a number of weak learners are combined to create a strong learner. The key steps in this process are as follows:
The picture below represents the boosting technique:
Boosting is important to data scientists because it can help them create models that are more accurate. Boosting works by taking several different models and averaging their predictions together. This helps to reduce the variance of the predictions and create a more accurate prediction. Additionally, boosting can help data scientists adjust the weights of the models so that the better models have more influence on the final prediction. This can help to improve the accuracy of the prediction.
One example of a real-world application of boosting is the use of boosted trees for predictive modeling. Boosted trees are a type of machine learning model that can be used to predict outcomes based on input data. They are especially useful for problems that are difficult to solve using other machine learning models. Boosted trees are created by combining the predictions of several different tree-based models. This helps to reduce the variance of the predictions and create a more accurate prediction. Additionally, boosting can help data scientists adjust the weights of the models so that the better models have more influence on the final prediction. This can help to improve the accuracy of the prediction.
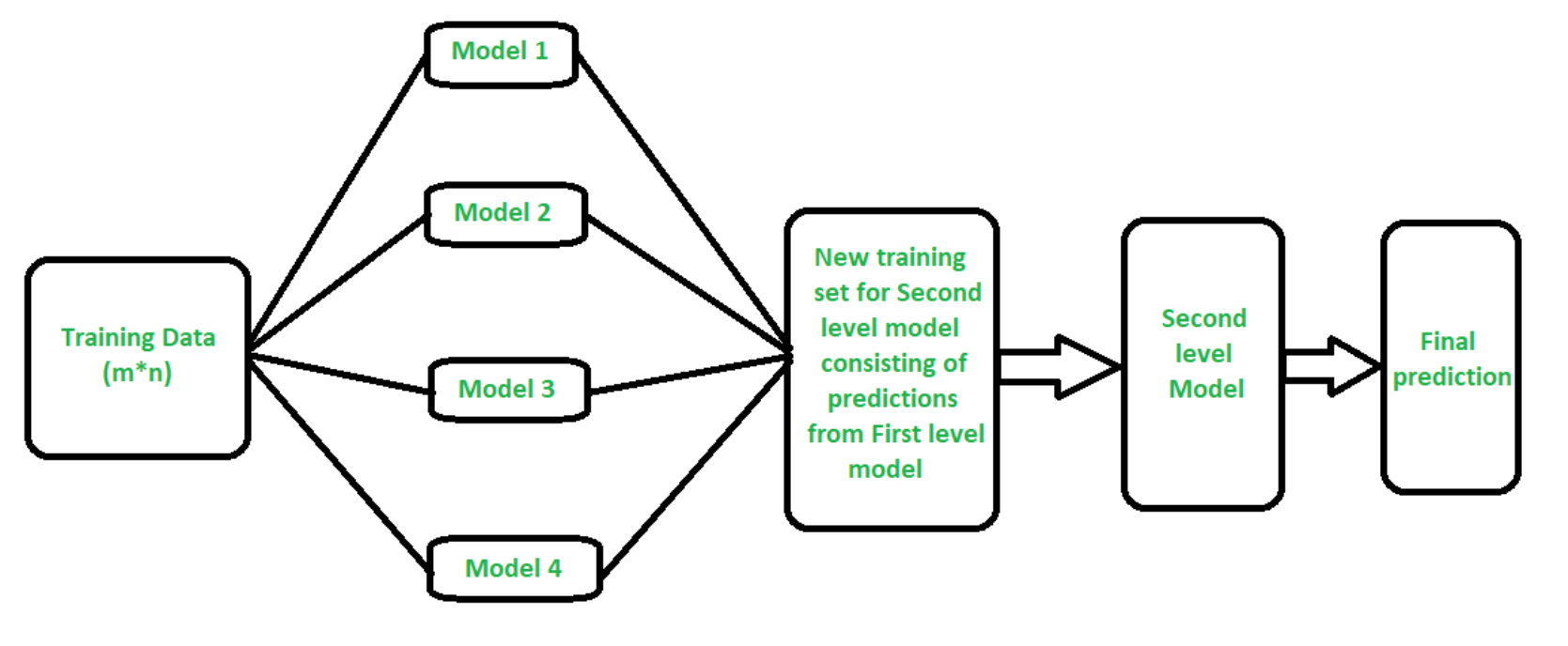
The stacking ensemble method is a machine learning technique that combines multiple models to produce a more accurate prediction. The models are “stacked” on top of each other, and the predictions from each model are combined to produce a final prediction. The stacking ensemble method can be used for regression or classification tasks, and it has been shown to outperform traditional machine learning methods. The stacking ensemble method is powerful because it can combine the strengths of different models to produce a more accurate prediction. However, the stacking ensemble method is also difficult to implement, and it requires a great deal of tuning to get the best results. The picture below represents stacking ensemble technique:
The stacking ensemble method can be used for solving a variety of machine learning problems, such as regression and classification. For example, imagine that you are trying to predict the price of a house. You could use a model to predict the price of a house based on its size and location, and then use a second model to predict the price of a house based on its age and condition. The predictions from each model would be combined to produce a final prediction for the price of the house. The stacking ensemble method is powerful because it can combine the strengths of different models to produce a more accurate prediction.
The stacking ensemble method is also difficult to implement, and it requires a great deal of tuning to get the best results. For example, you need to carefully select the models that you want to use in the ensemble. You also need to tune the parameters of each model to get the best performance. And finally, you need to select the optimal combination of models and parameters to produce the best results. The stacking ensemble method is powerful, but it is also difficult to use.
If you are looking for a machine learning method that is both powerful and easy to use, then you should consider using a different method. The stacking ensemble method is powerful, but it is also difficult to use. If you are looking for a machine learning method that is both powerful and easy to use, then you should consider using a different method.
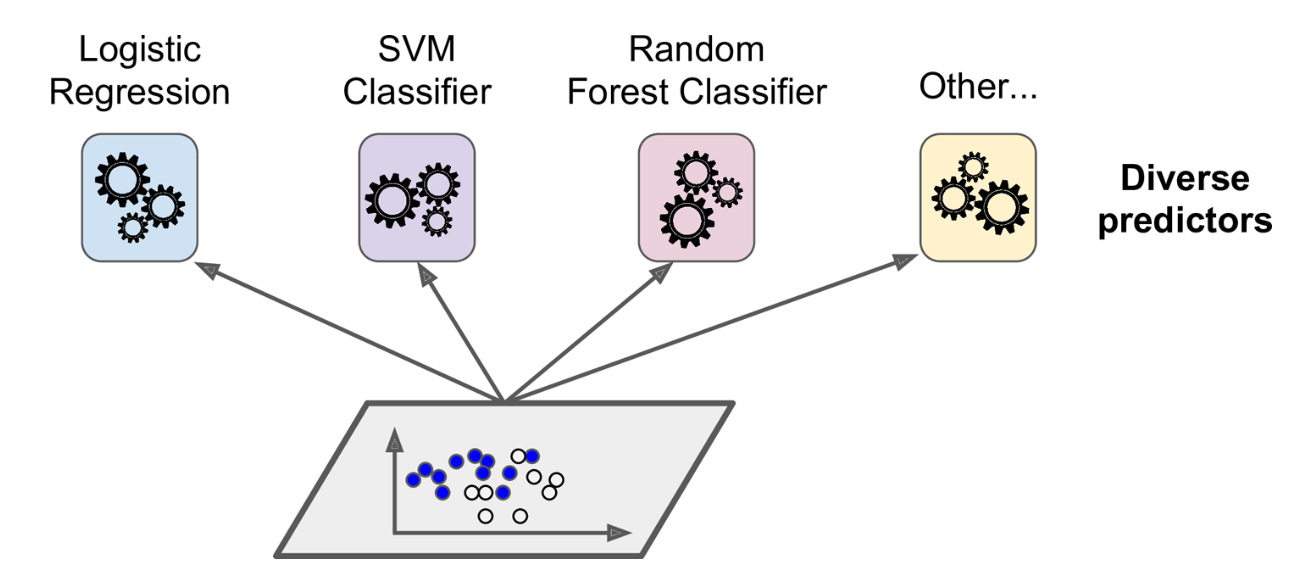
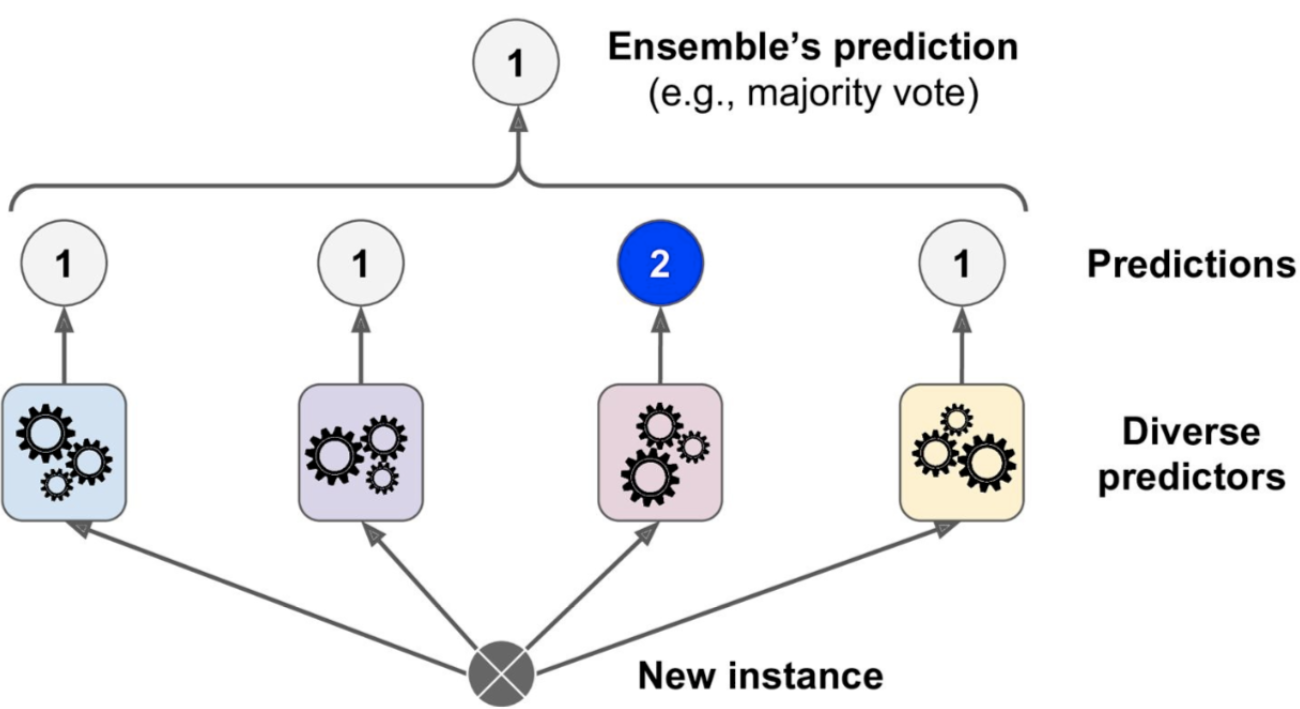
The voting ensemble method is a type of ensemble method that combines the predictions of multiple models by Voting. The voting ensemble method can be used to make more accurate predictions than any single model by combining the knowledge and expertise of multiple experts. The idea is that, by pooling the predictions of multiple models, you can reduce the variance and avoid overfitting. The voting ensemble method is typically used when there are multiple models with different configurations / algorithms. The following represents classifier ensemble created using models trained using different machine learning algorithms such as logistic regression, SVM, random forest and other algorithms.
In either case, the voting ensemble method can help to produce a more accurate prediction by aggregating the information from multiple sources. The above ensemble classifier aggregates the predictions of each classifier and predict the class that gets the most votes. This majority-vote classifier is called a hard voting classifier The picture below represents the hard voting to make the final prediction:
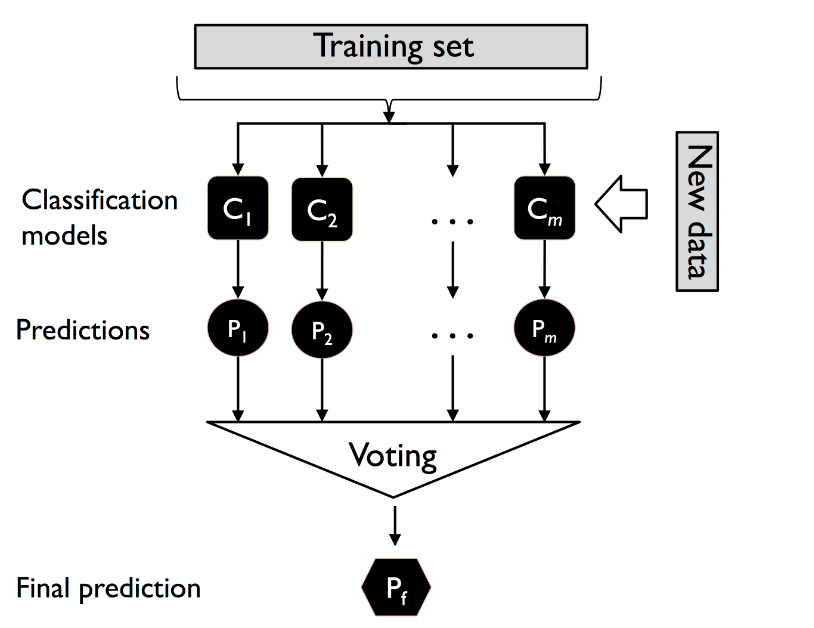
Here is another picture which can help understand the voting technique in a better manner. In the picture below, C represents classification models and P represents prediction. Training data set is used to train different classifications models C1, C2, …, Cm. Then, new data is passed to each of the classification models to get the predictions. Finally, the majority voting is used for final prediction.
Here is the sample code for Voting Classifier using Sklearn.
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.metrics import accuracy_score
#
# Load IRIS dataset
#
iris = datasets.load_iris()
X = iris.data
y = iris.target
#
# Create training and test data split
#
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
#
# Create classifier using logistic regression, randomforest and SVM
#
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
#
# Create Voting Classifier
#
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
#
# Fit the model
#
voting_clf.fit(X_train, y_train)
#
# Print the metrics
#
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
One example of a real-world problem that can be solved by the voting ensemble method is predicting the outcome of an election. By combining the predictions of multiple models, you can produce a more accurate prediction of who will win the election. This can be helpful for political campaigns, news outlets, and voters themselves.
Averaging is a simple yet powerful technique that can be used to improve the performance of machine learning models. The idea behind averaging is to combine the predictions of multiple models, weighting each model according to its accuracy. Averaging is an ensemble method, which means that it relies on the underlying strength of multiple models to produce a more accurate prediction. In practice, averaging is often used to combine the predictions of different machine learning algorithms. For example, a common approach is to train a number of different models on the same data and then average their predictions. Averaging can also be used to combine the predictions of multiple models trained on different data sets. This approach is known as cross-validation averaging. Averaging is a powerful technique that can help to improve the accuracy of machine learning models. However, it is important to remember that the success of averaging depends on the underlying strength of the individual models. If the models are not accurate, then averaging will not improve the performance of the resulting model.
One example of a real-world problem that can be solved by averaging is predicting the stock market. By combining the predictions of multiple models, you can produce a more accurate prediction of the stock market. This can be helpful for investors and financial analysts. Another example of a real-world problem that can be solved by averaging is predicting the weather. By combining the predictions of multiple models, you can produce a more accurate prediction of the weather. This can be helpful for people who need to plan outdoor activities. Averaging is a powerful technique that can help to improve the accuracy of machine learning models. However, it is important to remember that the success of averaging depends on the underlying strength of the individual models. If the models are not accurate, then averaging will not improve the performance of the resulting model.
Here are few key takeaways in relation to different ensemble methods in machine learning:
Machine learning models can be improved by using ensemble methods. These are techniques that combine the predictions of multiple models to produce a more accurate prediction. The most common type of ensemble method is averaging, which combines the predictions of multiple models weighted according to their accuracy. Other types of ensemble methods include bagging, boosting, stacking, and voting. Ensemble methods are a powerful tool for data scientists that can help to improve the accuracy of machine learning models. However, it is important to remember that the success of ensemble methods depends on the underlying strength of the individual models. If the models are not accurate, then ensemble methods will not improve the performance of the resulting model.
I hope you enjoyed this blog post! If you have any questions, please feel free to leave a comment below.
We’ve all been in that meeting. The dashboard on the boardroom screen is a sea…
When building a regression model or performing regression analysis to predict a target variable, understanding…
If you've built a "Naive" RAG pipeline, you've probably hit a wall. You've indexed your…
If you're starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation).…
If you've spent any time with Python, you've likely heard the term "Pythonic." It refers…
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}